Creative Commons and the Face Recognition Problem
How Creative Commons Licenses are Enabling and Accelerating Biometric Surveillance Technologies #
Research for OpenFuture.eu for the #AICommons project but opinions are my own. Written 2021-2022. Published May 25, 2022.
%%{init: {'theme':'base'}}%%
graph TD
CC[(Creative Commons Images)]:::CC
CC-->OpenImages[(OpenImages
fa:fa-images 9M)]
CC-->COCO[(COCO
fa:fa-images 100K)]
CC-->IJBC[(IJB-C
fa:fa-user 33K)]
CC-->PIPA[(PIPA
fa:fa-user 11K)]
CC-->GeoFaces[(GeoFaces
fa:fa-user 3M)]
CC-->FFHQ[(FFHQ
fa:fa-user 70K)]
CC-->GoogleFEC[(Google FEC
fa:fa-user 30K)]
CC--->YFCC100M[(YFCC100M
fa:fa-images 100M)]
YFCC100M-->MF[(MegaFace
fa:fa-user 3.7M)]
YFCC100M-->DIF[(IBM DiF
fa:fa-user 1M)]
YFCC100M-->FairFace[(FairFace
fa:fa-user 10K)]
YFCC100M-->FDF[(Flickr Diverse Faces
fa:fa-user 10K)]
YFCC100M-->WGT[(Who Goes There
fa:fa-user 660K)]
MF-->DiveFace[(DiveFace
fa:fa-user 139K)]
MF-->TinyFace[(TinyFace
fa:fa-user 10K)]
style CC fill:#fff,stroke:#000,stroke-width:2px,color:#000,stroke-dasharray: 5 5;
classDef someclass fill:#f96;
classDef docclass fill:#fff,stroke:#999;
classDef classLegend fill:#fff,stroke:#666,font-size:13px,text-align:left,line-height:20px,height:100px;
The metamorphosis of photographic data: From the initial photograph to license selection, every stage is a dataset transformation towards increasingly structured data. Between 2004 and 2022 over 20 billion photos were uploaded to Flickr.com, of which over 500 million used a Creative Commons license. In 2014 approximately 100 million of these Creative Commons licensed photos were selected for the YFCC100M dataset.
Recently, a debate has emerged over whether Creative Commons licenses are still relevant in the context of how images are being collected, used, and distributed in image training datasets related to the development of artificial intelligence (AI) and in particular face recognition technologies (FRT).
Research and numerous unsettling investigations during the last several years exposed a rift between how Creative Commons (CC) was originally designed to be used and its current prevalence in training datasets for AI systems, many of which have direct application to commercial mass surveillance technologies. Statements from the Creative Commons organization in 2019 tried to address the issue, explaining that Creative Commons licenses were simply designed to facilitate “greater openness for the common good” by unlocking copyright.
This report unfolds how licenses once designed to facilitate “openness for the common good” have been misinterpreted to eventually become synonymous with a misguided “free and legal for all” logic that often ignores the legal requirements of the Creative Commons license framework. The research presented below is only the tip of the iceberg. What is available publicly through analyzing research papers and GitHub repositories is a fraction of what happens behind closed doors, in proprietary systems, and by security agencies. The goal of this report is to provide context and accessible information on a technical topic with the intention of eventually helping to facilitate new image license schemes better suited to protect Internet users and creators in an era of increasingly data-driven artificial intelligence systems.
Unless otherwise noted, this report uses “Creative Commons” in reference to the concept of the commons and the license, not the organization, which is referred to herein as the “Creative Commons organization”.
The views expressed in this report are the views of the author and do not necessarily reflect the views of OpenFuture.eu or the #AICommons project.
A glossary is provided at the end of the page to expand technical terms, abbreviations, and concepts including training dataset, face recognition vs face detection, face embeddings, and scraping. Please scroll to the bottom of this page for help. The remainder of the report assumes familiarity with glossary terms.
The report contains a few unlinked citations due to limitations of the publishing software. They appear in [brackets] within the expandable sections.
Introduction #
Artificial Intelligence (AI), Computer Vision (CV), and Machine Learning (ML) systems rely on vast quantities of data to train neural networks. In computer vision, recent breakthroughs in deep convolutional neural networks (DCNN) have enabled a rapid expansion of advanced image and video analysis technologies, especially face recognition. The new wave of DCNN-based face recognition has outright replaced a previous generation of computer vision technologies.
In a 2019 hearing before the United States House Homeland Security Committee examining the government use of facial recognition, NIST (National Institute for Science and Technology) director Dr. Charles Romine stated the recent advances in face recognition technologies amount to a “gamechanger”. The reason, Romine explains, for the increased “accuracy and capabilities of the systems we’ve seen in past years” is “the advent of convolutional neural networks and machine learning capabilities to do the image analysis.1 According to Dr. Romine, facial recognition based on convolutional neural networks have completely replaced older technologies.2
When experts point to breakthroughs in machine learning and DCNNs, they often ignore the data component. Dr. Romine also mentioned that performance breakthroughs in the best face recognition systems depend on “suitable training”, but doesn’t elaborate further. Suitable training for a face recognition system would require millions, tens of millions, or even hundreds of millions of faces. Getting access to that data is the hidden gamechanger in face recognition systems.
Face recognition companies and researchers are often reluctant to disclose where their training data is from. Though without real faces of real people their systems would not work. In the past several years, research from Exposing.ai (the research project behind this report), has helped pushed this issue into the open. Citing research from Exposing.ai, a 2019 story from the Financial Times reported that students on multiple U.S. campuses were being surreptitiously surveilled and used as training data for research linked to military applications. Another dataset, created by Microsoft, scraped millions of faces from the Internet to create a massive face recognition dataset called MS-Celeb-1M. Another story from NBC found over million people’s faces used in the IBM Diversity in Faces (DiF) dataset that led to a class action lawsuit again IBM. Yet another story from The New York Times story published an investigation into the MegaFace dataset revealing that family and weddings photos were used for commercial, defense, and law enforcement projects. Then, Brett Gaylor, a Canadian citizen and filmmaker, found his honeymoon photos in the MegaFace and IBM DiF dataset and made a film about it. Meanwhile, as part my ongoing research for Exposing.ai, I created a search engine to check if your Flickr photos were used in datasets to help move the discussion further. The discussion can be difficult because it is technically pedantic.
After the series of shocking stories about face datasets, there was a reckoning of sorts, but not much has changed. Shortly after several datasets were retracted they would reappear on torrents or in were cloned to new GitHub repositories. Datasets are just too important to go away on their own. Datasets are the lifeblood of AI. When combined with deep convolutional neural networks, datasets perform what could even be considered a new kind of programming altogether. Because programming AI means programming with data, Geoffrey Hinton, a progenitor of deep learning, thinks that “our relationship to computers has changed”. “Instead of programming them, we now show them and they figure it out.”3 AI expert Kai-Fu Lee says “AI is basically run on data.” “The more data the better the AI works, more brilliantly than how the researcher is working on the problem.”4 Few disagree with this logic. Even the president and CEO of In-Q-Tel, a CIA subsidiary, says “an algorithm without data is useless.”5 Datasets are part and parcel of AI. Without data input there is no AI output. Though, strangely, there is relatively little known about the origins, contents, and endpoints of image input used in AI and in particular face recognition.
During research for the Exposing.ai project (a precursor to this report) it became clear that a lot of the training data used in AI systems is coming from Creative Commons licensed media. This was discovered by trawling tens of thousands of academic research papers on sites like Arxiv and Semantic Scholar and monitoring international computer vision conferences. Most of these research projects collected and used “media in the wild”, a term used to describe images taken without consent, or in the “natural” environment. Non-consensual or “wild” media has played a major role in training AI systems which need real-world data to understand real-world scenarios.
To obtain massive quantities of “media in the wild”, researchers and developers increasingly turned to the Internet as a primary data source because it’s scalable, quick, free, and seemingly legal. One of the main keys to unlocking this type of data has been the Creative Commons (CC) license. In AI research communities, Creative Commons is considered free and legal data with virtually no restriction. The most that creators can expect from having their work included in ML datasets appears to be having their metadata dumped into a JSON file that is often too large to be opened. In other words ML researchers and companies get free data and creators get nothing. This amounts to a basic definition of exploitation.
Creative Commons data exploitation is less problematic when images are used for datasets like “FlickrLogos-32”, a collection of logos in photos used for logo detection. But can become highly problematic and possibly illegal when used as biometric data by commercial organizations and defense contractors in datasets such as MegaFace, a collection of 3.3 million face photos from Flickr used in a worldwide face recognition competition. It can become even more problematic when names are included with biometric data. Because Creative Commons requires attribution this can create a Catch-22. CC licensed photos used in face recognition not only include biometric data but also real names. And since all CC licensed media (except CC0) require attribution, a CC-licensed face photo used as biometric data in the EU or US would either violate CC or biometric laws (GDPR in the EU, or BIPA in the US).
Creative Commons and Flickr #
To understand the significance of the relationship between Creative Commons, Flickr, and face recognition it is helpful to begin with an introduction to Flickr; a website designed for photographers to share images with the world, receive feedback, and develop communities around shared interests. Flickr users have the option of making their uploads private or public, and can choose from various Creative Commons, copyright, or public domain licenses to help others find and use their images. Flickr was founded in 2004 and quickly became popular with photographers and visual creators as a place to host files, share and discover creative work. Within five years, Flickr hosted over 100 million Creative Commons licensed images.6 By 2022, Flickr hosts over 467 million Creative Commons licensed images7 and “tens of billions of photos”8 total with other licenses or private. Understanding tens of billions to mean a minimum of 20 billion equates to a maximum of 2.3% Creative Commons license usage across all photos on Flickr. The vast majority (97.7%) of photos currently on Flickr do not use Creative Commons license, though 467 million is still an impressively large number.
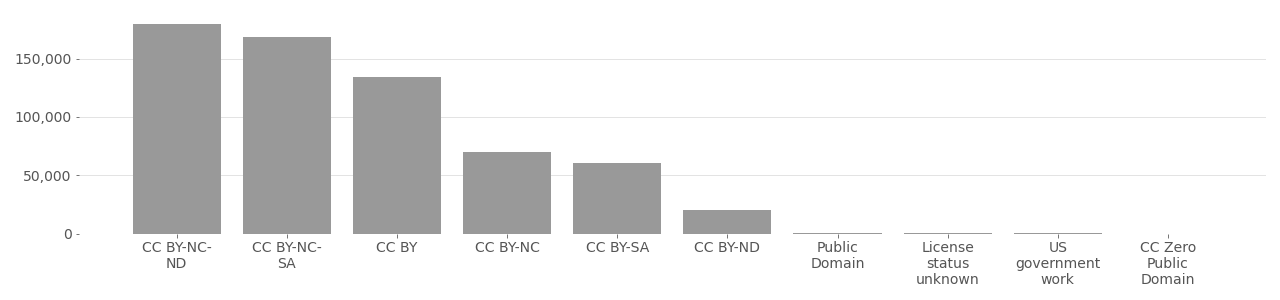
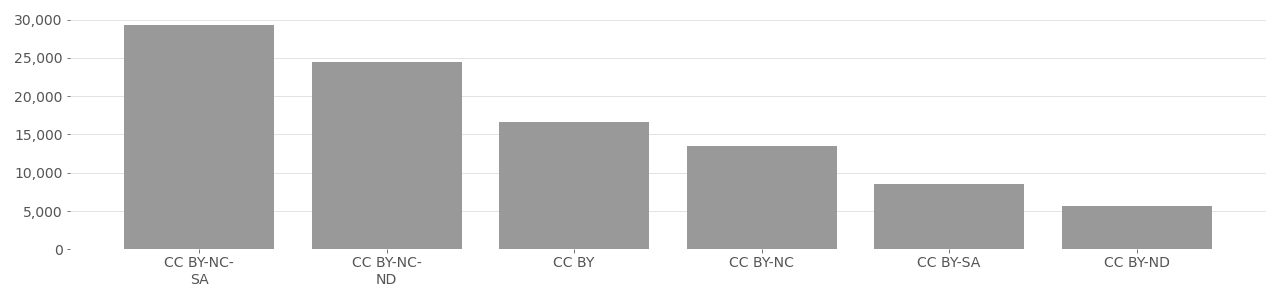
Of the 467 million Creative Commons licensed media, 97% use a license with at least one restrictive clause (e.g. CC-BY or CC-NC), while less than 1% use CC0 (a Creative Commons public domain dedication). Split by restrictive clauses, the most frequently used combination from the possible options including BY, NC, ND, and SA is the combination CC-BY-NC-SA (27%)), meaning the image can only be used non-commercially, with attribution, and the user must also share their work with a CC license. Filtering by single restrictive clauses, the most common is non-commercial (CC-BY-NC) at 33%, followed by attribution only (CC-BY) at 27%, and then share-alike (CC-BY-SA) at 26%. Statistically, most Flickr users do not with to share their work using CC licenses (only about 2.3%), but within this small minority, data shows that most important restrictions are prevent others from exploiting their work with credit or compensation. Overwhelmingly, this correlates to high demand for control over user generated content posted to Flickr. Only 0.015% of images shared to Flickr think any use of their work is acceptable, while 2.3% impose restrictions through a CC license, and 97.7% would rather not share using CC license. Tables below show data available from Flickr accessed February 3, 2022.
Table 1: What Are The Most Popular CC Licenses on Flickr.com?
| License | Abbreviation | Count | Percent |
|---|---|---|---|
| Attribution-NonCommercial | CC-BY-NC-SA | 129,743,321 | 27.14% |
| Attribution-NonCommercial-NoDerivs | CC-BY-NC-ND | 111,833,568 | 23.39% |
| Attribution-NonCommercial-ShareAlike | CC-BY-NC | 60,766,952 | 12.71% |
| Attribution | CC-BY | 90,776,696 | 18.99% |
| Attribution-ShareAlike | CC-BY-SA | 46,923,360 | 9.82% |
| Attribution-NoDerivs | CC-BY-ND | 23,951,348 | 5.01% |
| Public Domain Mark | PD | 10,232,110 | 2.14% |
| Public Domain Dedication | CC0 | 3,803,923 | 0.8% |
See glossary for expanded definition of each CC license. Count is inclusive of both photos and videos. Creative Commons restriction distribution based on data from https://www.flickr.com/creativecommons. Accessed February 3, 2022.
Table 2: What Percentage of Photos on Flickr are Creative Commons Licensed?
| License | Abbreviation | Count | Percent |
|---|---|---|---|
| CreativeCommons Attribution (inc. ND, NC, SA) | CC-BY-* | 463,995,245 | 2.27% |
| Public Domain and CC0 | PD, CC0 | 14,036,033 | 0.07% |
| All images | 467,799,168 | 97.67% |
See glossary for expanded definition of each CC license. Count is inclusive of both photos and videos.
Table 3: What Is The Most Popular Creative Commons License Clause?
| License | Abbreviation | Count | Percent |
|---|---|---|---|
| NonCommercial and any other | BY-NC-* | 302,343,841 | 48.88% |
| NoDerivs and any other | BY-ND-* | 135,784,916 | 21.95% |
| ShareAlike and any other | BY-SA-* | 176,666,681 | 28.56% |
See glossary for expanded definition of each CC license. Count is inclusive of both photos and videos.
Creative Commons and Datasets #
Scraping faces from the Internet is, unfortunately, not new nor limited to Creative Commons images. Years before Flickr and Creative Commons existed researchers at University of Massachusetts Amherst wrote software to scrape images from Yahoo News. Between 2002 - 2004 they collected thousands names and faces for the aptly named “Names and Faces in the News” dataset. In 2007 it was expanded and republished as “Labeled Faces the Wild” (LFW), eventually becoming the most well known, used, and referenced publicly available face recognition dataset on the Internet. But, no one in LFW knew anything about it. Unlike previous face recognition including FERET and PIE, there were no more consent forms or photography fees, and most importantly the photos were a closer match to the surveillance imagery face recognition was being designed for. As of January 2022, the LFW dataset is still free for anyone to use anywhere for any academic, commercial, or even military application with no legal restrictions. Terms of use? None. The LFW dataset was a huge step forward for face recognition, a huge step backwards for privacy, and major stepping stone into the next two decades of unregulated biometric data collection “in the wild”.
Since the publication of LFW in 2007, collecting images (face and non-face) “in the wild” (without consent) for machine learning research has become standard practice. Among the first widely used machine learning datasets for computer vision created using Flickr images are PASCAL VOC (2007) and MIRFLICKR-25K9 (2008). Though neither was created for face recognition research their success helped facilitate the normalization of Creative Commons images in machine learning datasets, setting a precedent for more “media in the wild” to follow in the next decade. Since publication, research papers associated with MIRFLICKR and PASCAL VOC received over 1,000 and 10,000 academic citations respectively.
By 2010, Flickr’s popularity with photographers and Creative Commons enthusiasts was soaring. In 2009 there were over 100 million Creative Commons licensed shared on Flickr. The alluring combination of permissive licensing and million-scale media “in the wild” piqued the interests of an unlikely grouping of researchers from Lawrence Livermore National Laboratory (LLNL), Berkeley, Yahoo Labs, Snapchat and, In-Q-Tel. LLNL is a self-described “premier research and development institution for science and technology applied to national security”10, In-Q-Tel is a subsidiary and research group of the Central Intelligence Agency, while Snapchat is merely a picture messaging app primarily for teenagers (or is it?). In 2014 they jointly published a massive corpus of Creative Commons imagery from Flickr named Yahoo! Flickr Creative Commons 100 Million (YFCC100M). At the time, it was the largest ever publicly available image dataset for computer vision and machine learning. The dataset is public and can be downloaded by anyone. However, the “dataset” does not include images, only metadata. The full download is a 12.5GB compressed text file with Flickr URLs and the user-generated metadata including image license, location (when embedded in the EXIF data), date, image tags, username, and camera information.
Despite its simple existence as text file of URLs and Creative Commons licenses, YFCC100M is among the most influential computer vision datasets of all time. In the research paper “YFCC100M: The New Data in Multimedia Research” announcing the dataset, the authors make an attractive but misleading claim that the dataset is “free and legal to use.”11 This was picked up by a journal from the Association for Computing Machinery (ACM) that boldly summarized YFCC100M as a “publicly available curated dataset of almost 100 million photos and videos is free and legal for all.” This misrepresents Creative Commons and set a false precedent for other researchers that reverberated throughout academic and industry research communities, though perhaps that was the intention. The authors also mentioned that “[s]hared datasets can play a singular role in achieving research growth and facilitating synergy within the research community that is otherwise difficult to attain.”11 By offering a list of 100 million Flickr image URLs that are “free and legal to use” for machine learning research, the institutional sheen behind YFCC100M effectively provided a legal smokescreen that helped pave the way for a large-scale exploitation of Flickr photos.

A misleading headline in an ACM journal described the YFCC100M dataset as a dataset of approximately 100 million photos that “free and legal for all.”
To understand how images were used, the following datasets were selected to represent various issues. The main criteria is reliance on Creative Commons licenses as rationale for constructing the dataset. All datasets listed below relied in majority on Creative Commons licenses as justification for using the images. Dozens, possibly hundreds, more datasets exist that use Flickr or Creative Commons licensed imagery.
Table: Face Analysis Datasets Relying on Creative Commons as Full Source of Imagery
| Dataset | Year | Images | Purpose | Origin | URL | Active | Types of Images |
|---|---|---|---|---|---|---|---|
| DiveFace | 2019 | 139,677 | Face recognition | YFCC100M | GitHub | Y | |
| FairFace | 2019 | 108,501 | Face recognition | YFCC100M | GitHub | Y | |
| Flickr Diverse Face (FDF) | 2019 | 1,080,000 | Face recognition | YFCC100M | GitHub | Y | |
| Flickr Faces High-Quality (FFHQ) | 2018 | 70,000 | Face synthesis | Flickr API | GitHub | Y | |
| GeoFaces | 2019 | 1,080,000 | Ethnicity recognition | YFCC100M | GitHub | Y | |
| Google FEC | 2018 | 87,517 | Face expression | Google Internal Flickr Dataset | research.google | Y | |
| IBM DiF | 2019 | 1,070,000 | Face recognition | YFCC100M | IBM.com | N | |
| IJB-C | 2017 | 11,799 | Face recognition | Flickr API | NIST.gov | Y | |
| MegaFace | 2016 | 4,753,520 | Face recognition | YFCC100M | washington.edu | N | |
| COCO | 2014 | 328,000 | Object detection | Flickr API | cocodataset.org | Y | |
| PIPA | 2015 | 37,107 | Face recognition | Flickr API | mpg.de | Y | |
| Who Goes There | 2019 | 1,080,000 | Ethnicity recognition | YFCC100M | cs.uku.edu | Y | |
| YFCC100M | 2014 | 100,000,000 | Machine learning | Flickr API | opendata.aws | Y |
= Face images. = all types of images. Table includes only datasets that use majority Creative Commons imagery.
Creative Commons is not only a license but also a dataset. Adding a CC license also adds the image to machine readable dataset. CC imagery can be more easily downloaded or scraped compared to images search engine results. In addition to the permissive licenses requirements, this makes CC an ideal source of data for machine learning, computer vision, and AI developers.
Datasets #
COCO Dataset
COCO #
COCO (Microsoft Common Objects in Context), also MS-COCO, is a dataset of images taken from Flickr.com primarily used for developing object detection computer vision algorithms. COCO was published in 2014 and contains about 328,000 total images. Among these are 59,144 photos with the class person. COCO is included in this analysis because it is entirely comprised of Flickr images using Creative Commons licenses and has overlap to the development of surveillance technology. Based on an analysis of only the “person” class, which is the category most closely associated with potential surveillance applications, 57,245 out of 59,144 images used a Creative Commons license, and of those 57,245 Creative Commons licenses over 99% required attribution, for which 0% was provided.
The COCO dataset download includes images and JSON metadata files. The images included in the dataset distributed by
https://cocodataset.org/ are the original images downloaded from Flickr. Each image in the COCO dataset is described in a JSON file that includes Flickr metadata about the image’s origin and annotation data associated with the image. The JSON metadata includes a number indicating the license designation and the full URL to the image JPG file. However, COCO omits attribution, a legal requirement of Creative Commons licenses. The JSON metadata includes three sections: a file version header, license metadata, and image metadata. An unaltered sample of data from instances_train2017.json is provided at the bottom of this section.
COCO is a foundational dataset for object detection. It is the most widely used image dataset for benchmarking object detection algorithms and in pre-trained object detection models that can then be customized using fine-tuning and transfer-learning for application to specific computer vision tasks. The COCO dataset authors highlight the importance and value of the dataset not for it’s specificity in detecting any certain object but instead for its general utility as an innovation driver, noting that “[t]hroughout the history of computer vision research datasets have played a critical role. They not only provide a means to train and evaluate algorithms, they drive research in new and more challenging directions”. Indeed, COCO is one of the main drivers of growth in object detection research, development, and innovation and has contributed in immeasurable ways to the growth of multi-billion dollar technology corporations, including Microsoft who contributing funding for the dataset (and is apparently involved in the ongoing development) along with a grant from the Office of Naval Research Multidisciplinary University Research Initiative ( ONR MURI, a Department of Defense funding program).
The COCO dataset is highly relevant to discussions about Creative Commons because the dataset authors relied exclusively on CC images for the dataset. They considered the combination of permissive licenses and ordinary, accessible photos to be ideal for their computer vision dataset because Flickr “tends to have fewer iconic images” and provides “searchable metadata and keywords.”[^coco] In comparison, search engine results are noisy, do not include image metadata, typically omit licensing information, and include staged product photos and commercial graphics.
An email inquiry to the COCO consortium, who operates the cocodataset.org site, received a confirmation on June 25, 2021 that they ‘did not attach the Flickr photographer/creator in the annotation file. The “flickr_url” is the original source of the image." However, the Flickr URL only points to the JPG file (eg http://farm9.staticflickr.com/########/####_#####.jpg) not the Flickr photo host page. This means it is not possible to know or attribute the creator without writing a script to query the Flickr API with the photo ID to obtain the photo source URL or using the Flickr API demo page to manually query the photo ID. Additionally, photos may have been removed Flickr after the creation of COCO and Flickr API data would not be available. COCO provides a clear example of large-scale CC violation by its clear omission of attribution, denying the creators of 328,000 images of their legally required credit. It may also be considered a commercial use of non-commercial images. This could amount to a substantial violation considering that the COCO is a foundational dataset that has likely been downloaded and used in tens of thousands of research projects. According to one
valuation metric used by Microsoft’s Trove experiment, each photo use could be worth approximately $0.50 or $165,000 per dataset usage.
{kind=link}
COCO provides a clear example of how the legal Creative Commons licenses were ignored for profit-driven applications by a large corporation with eventual technical value transfer related to the funding partner ONR MURI (a Department of Defense initiative). As evidence of this eventual usage, a 2016 slide deck from a briefing between the Office of Director of National Intelligence (ODNI) and the Intelligence Advanced Research Projects Activity (IARPA) shows that the IC (Intelligence Community) considers images from several object classes in COCO valuable for their work, namely: Person, Car, Truck, Backpack, and Knife. Therefore images in COCO have both commercial value and are applicable to defense related surveillance technologies.

The COCO image dataset is described as containing “relevant objects” in a slide for a defense and intelligence agency related research project.
COCO has also been used for many different tasks beyond object detection. The COCO dataset download page lists the following options:
Images
| Year | Task | Size |
|---|---|---|
| 2014 | Train images | 13GB |
| 2014 | Val images | 6GB |
| 2014 | Test images | 6GB |
| 2015 | Test images | 12GB |
| 2017 | Train images | 118GB |
| 2017 | Val images | 1GB |
| 2017 | Test images | 6GB |
| 2017 | Unlabeled images | 19GB |
Annotations
| Year | Task | Size |
|---|---|---|
| 2014 | Train/Val annotations | 241MB |
| 2014 | Testing Image info | 1MB |
| 2015 | Testing Image info | 2MB |
| 2017 | Train/Val annotations | 241MB |
| 2017 | Stuff Train/Val annotations | 1.1GB |
| 2017 | Panoptic Train/Val annotations | 821MB |
| 2017 | Testing Image info | 1MB |
| 2017 | Unlabeled Image info | 4MB |
COCO Image License Distribution (Person class)
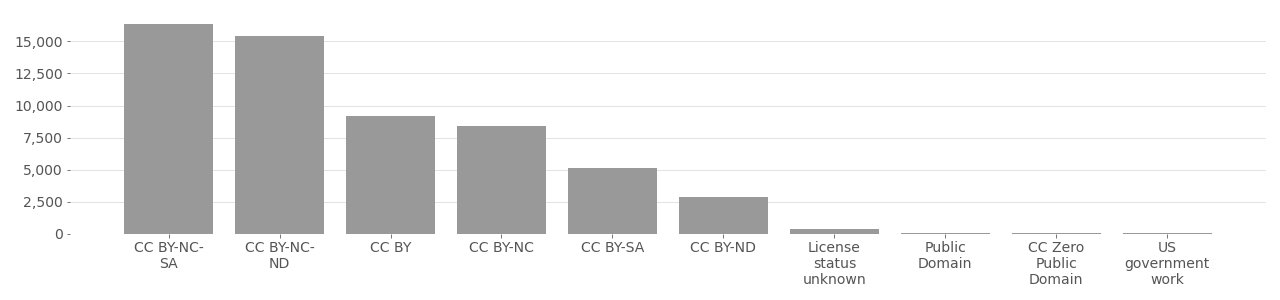
Based on metadata provided by Flickr API in 2020.
COCO Image Rights Distribution (Person class)
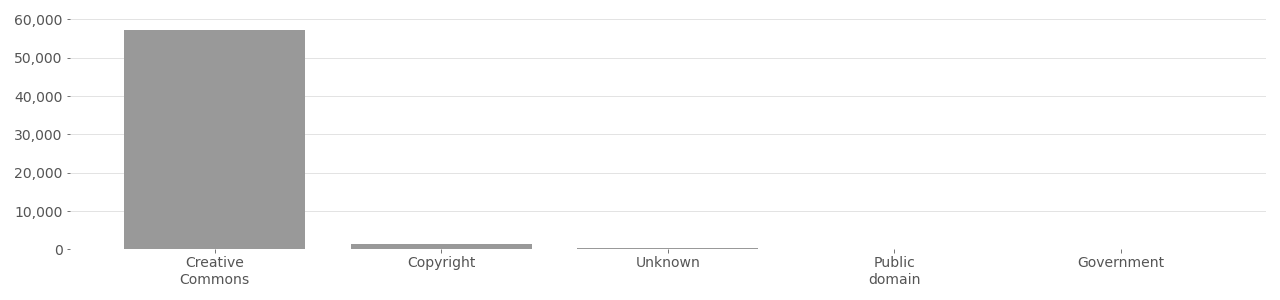
Based on metadata provided by Flickr API in 2020.
COCO Image Country Distribution (Person class)
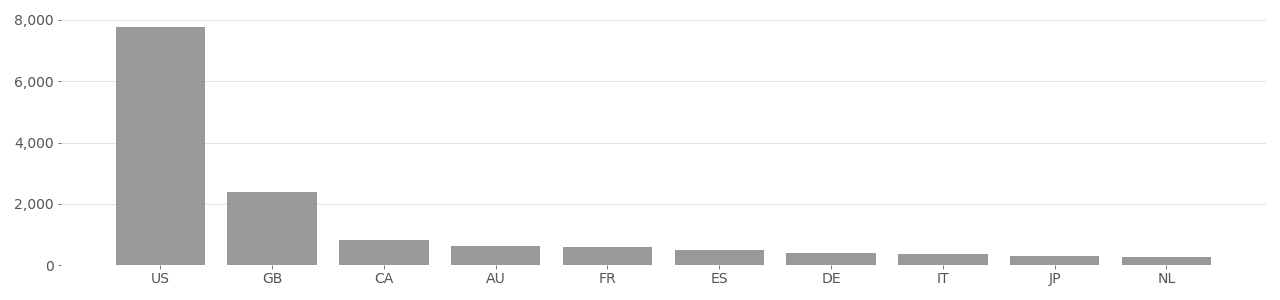
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
COCO Image Tag Distribution (Person class)
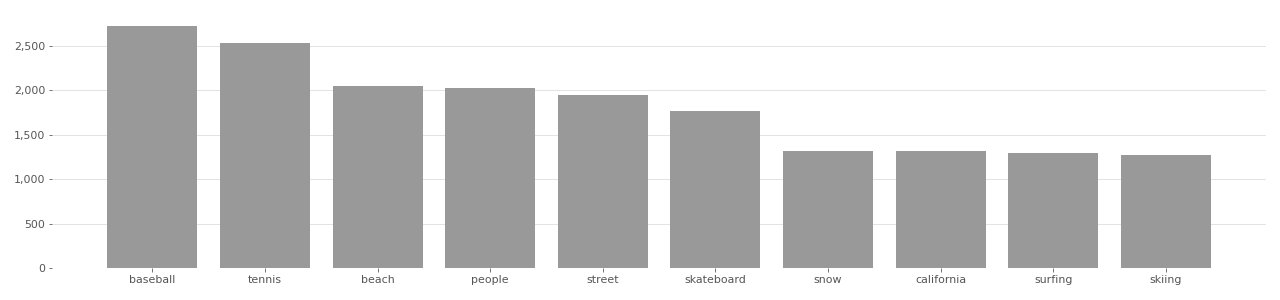
Based on user-supplied tags in metadata provided by Flickr API in 2020.
# Unaltered sample from COCO 2017 training images
{
"info": {
"description": "COCO 2017 Dataset",
"url": "http://cocodataset.org",
"version": "1.0",
"year": 2017,
"contributor": "COCO Consortium",
"date_created": "2017/09/01"
},
"licenses": [
{
"url": "http://creativecommons.org/licenses/by-nc-sa/2.0/",
"id": 1,
"name": "Attribution-NonCommercial-ShareAlike License"
},
...
],
"images": [
{
"license": 3,
"file_name": "000000######.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000######.jpg",
"height": 360,
"width": 640,
"date_captured": "2013-11-14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/##########_##########_z.jpg",
"id": 391895
},
...
The COCO dataset is provided in several different versions. The 2014 file instances_train2014.json includes the slightly different header information and same image information. It also implies that COCO belongs to Microsoft.
# Unaltered sample from COCO 2014 training images
{
"info": {
"description": "This is stable 1.0 version of the 2014 MS COCO dataset.",
"url": "http://mscoco.org",
"version": "1.0",
"year": 2014,
"contributor": "Microsoft COCO group",
"date_created": "2015-01-27 09:11:52.357475"
},
"images": [
{
"license": 5,
"file_name": "COCO_train2014_0000000#####.jpg",
"coco_url": "http://mscoco.org/images/57870",
"height": 480,
"width": 640,
"date_captured": "2013-11-14 16:28:13",
"flickr_url": "http://farm4.staticflickr.com/3153/##########_##########_z.jpg",
"id": 57870
},
...
A 2017 file entirely changed the format to only include image links to the COCO distribution site:
# Unaltered example from "image_info_test2017.json", part of the extended COCO dataset
"images":
[
{
"license": 6,
"file_name": "000000######.jpg",
"coco_url": "http://images.cocodataset.org/test2017/000000466319.jpg",
"height": 480,
"width": 640,
"date_captured": "2013-11-14 11:04:33",
"id": 466319
},
DiveFace
DiveFace is a dataset of photos used for face recognition. The dataset was published in 2019 and contains 139,677 images of about 24,000 individuals. According to the authors, “DiveFace contains annotations equally distributed among six classes related to gender and ethnicity (male, female and three ethnic groups).” The gender and ethnicity labels were generated using a combination of automatic facial feature analysis with manual labeling oversight. The authors describe each category according to the following logic [^Morales2020SensitiveNetsLA]:
- East Asian (Group 1): people with ancestral origin in Japan, China, Korea and other countries in that region.
- Sub-Saharan and South Indian (Group 2): people with ancestral origins in Sub-Saharan Africa, India, Bangladesh, Bhutan, among others.
- Caucasian (Group3): people with ancestral origins from Europe, North-America and Latin-America (with European origin).
The authors explain that they are “aware about the limitations of grouping all human ethnic origins into only 3 categories. According to different studies, there are more than 5K ethnic groups in the world. We made the division in these three big groups to maximize differences among classes. As we will show in the experimental section, automatic classification algorithms based on these three categories show performances up to 98% accuracy.”[^Morales2020SensitiveNetsLA]
Images in the DiveFace dataset are derived from the MegaFace dataset, which was derived from the Yahoo! Flickr Creative Commons 100 Million (YFCC100M) dataset, which is ultimately derived from the entirety of Flickr images uploaded between 2004 and 2014. Although YFCC100M and subsequently MegaFace and DiveFace are all comprised of Creative Commons images, there are important distinctions in the licensing.
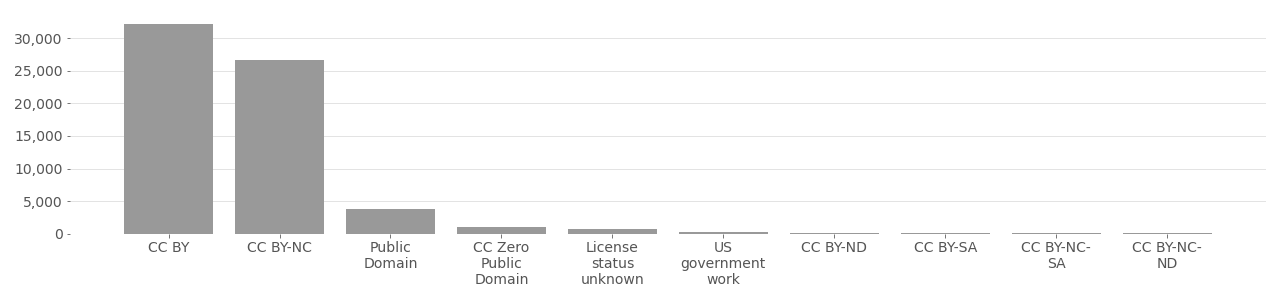
The DiveFace metadata can be downloaded from the author’s GitHub page at https://github.com/BiDAlab/DiveFace. Their research paper is available at https://arxiv.org/ftp/arxiv/papers/1902/1902.00334.pdf. The majority of images in DiveFace are licensed under a BY-NC-ND, which stipulates that users of their images must provide attribution (BY), only be used for non-commercial purposes (NC), and that no derivations (ND) are allowed. Graphs below show the license distribution.
DiveFace Image License Distribution
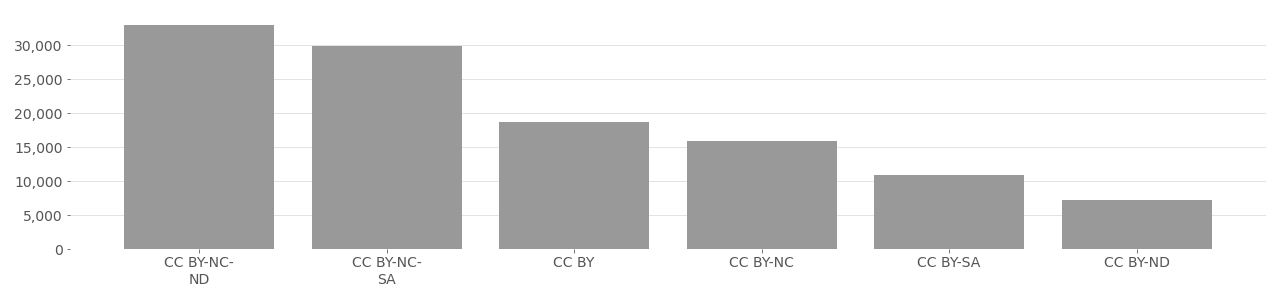
Based on metadata provided by Flickr API in 2020.
DiveFace Image Rights Distribution

Based on metadata provided by Flickr API in 2020.
DiveFace Image Country Distribution
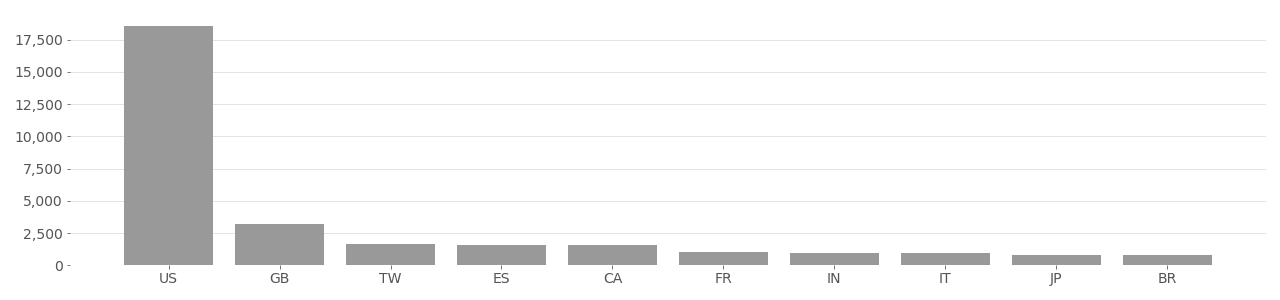
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
DiveFace Image Tag Distribution
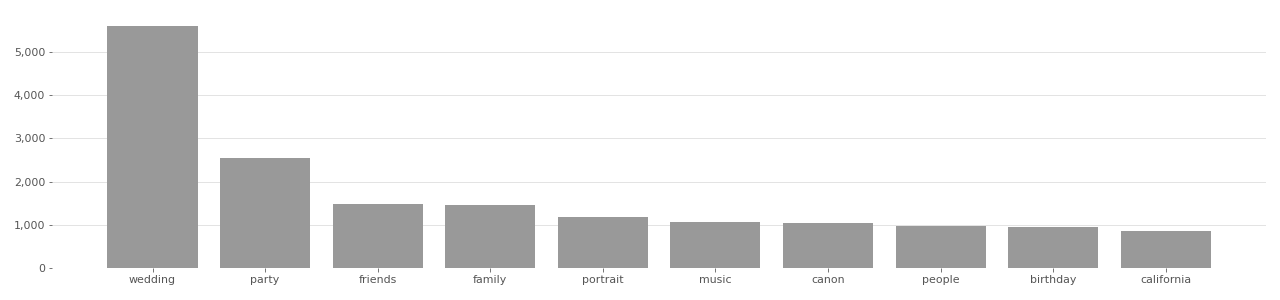
Based on user-supplied tags in metadata provided by Flickr API in 2020.
The “ancestral origin” data is specified by the filenames Group1_Female.txt, Group1_Male.txt, Group2_Female.txt, Group2_Male.txt, Group3_Female.txt, and Group3_Male.txt with each group number indicating the ethnicity label. Each text file only contains a filename based on the Flickr username and photo ID:
# unaltered data example from DiveFace dataset
100016927@N02_identity_1/9469948405_7.jpg
...
FairFace Dataset
FairFace #
FairFace: FairFace is a face recognition image dataset designed to be race balanced. It contains 108,501 images from 7 different race groups: White, Black, Indian, East Asian, Southeast Asian, Middle Eastern, and Latino. Most images were collected from the YFCC100M Flickr dataset and labeled with race, gender, and age groups. FairFace uses all Creative Commons licensed images and all images in FairFace are derived from YFCC100M.
The FairFace distribution page https://github.com/joojs/fairface provides zip files with over 2GB of imagery, but with no CC license metadata.
Although FairFace is presented as a “fair” alternative to other problematic face recognition datasets that underrepresent darker skin tones and females, adding more people to databases does not necessary equate with more fairness. Dr. Alex Hanna, a sociologist and researcher at Distributed AI Research (DAIR) institute, points out in her essay Lines of Sight, solving representational problems in image training datasets is not necessarily a move in the right direction, writing that when blaming algorithmic bias problems on “underrepresentation of a marginalized population within a dataset, solutions are subsumed to a logic of accumulation; the underlying presumption being that larger and more diverse datasets will eventually morph into (mythical) unbiased datasets.” For HuggingFace, an AI community centered on building more equitable tech-futures, providing free access to facial recognition dataset with racial classification labels probably does not align with those values.
Recently, the FairFace dataset was included for programmatic, automatic distribution on the AI platform HuggingFace. The dataset was integrated directly into the HuggingFace code enabling a programmer to bypass reviewing the licenses. Again, it appears that Creative Commons was misinterpreted as “free and legal for all”.
Within hours of being notified that their site was hosting the offending dataset, access to FairFace along with an additional errant webpage containing the actual biometric face-embeddings was removed by their CEO pending further review (( archive. Like IBM DiF and MegaFace, FairFace is another example of YFC100M’s long lasting and misleading effect of providing “free and legal for all,” a sentiment echoed in the DiveFace research paper: “[o]ur datasets contains 108,501 face images collected from the YFCC-100M dataset, which can be freely shared for a research purpose”[^fairface]
# unaltered data example from FairFace
file, age, gender, race, service_test
train/1.jpg, 50-59, Male, East Asian, TRUE
...
No license graphs are available for FairFace because the dataset does not include this information.
FDF Dataset
FDF #
Flickr Diverse Faces (FDF) is a dataset with 1.5M faces “in the wild”. FDF has a large diversity in terms of facial pose, age, ethnicity, occluding objects, facial painting, and image background. The dataset is designed for generative models for face anonymization, and it was released with the paper “DeepPrivacy: A Generative Adversarial Network for Face Anonymization.
{
"0": { // FDF image index
"author": "flickr_username",
"bounding_box": [], # List with 4 eleemnts [xmin, ymin, xmax, ymax] indicating the bounding box of the face in the FDF image. In range 0-1.
"category": "validation", # validation or training set
"date_crawled": "2019-3-6",
"date_taken": "2010-01-16 21:47:59.0",
"date_uploaded": "2010-01-16",
"landmark": [], # List with shape (7,2). Each row is (x0, y0) indicating the position of the landmark. Landmark order: [nose, r_eye, l_eye, r_ear, l_ear, r_shoulder, l_shoulder]. In range 0-1.
"license": "Attribution-NonCommercial License",
"license_url": "http://creativecommons.org/licenses/by-nc/2.0/",
"original_bounding_box": [], # List with 4 eleemnts [xmin, ymin, xmax, ymax] indicating the bounding box of the face in original image from flickr.
"original_landmark": [], # Landmark from the original image from flickr. List with shape (7,2). Each row is (x0, y0) indicating the position of the landmark. Landmark order: [nose, r_eye, l_eye, r_ear, l_ear, r_shoulder, l_shoulder]
"photo_title": "original_photo_name", # Flickr photo title
"photo_url": "http://www.flickr.com/photos/.../", # Original image URL
"yfcc100m_line_idx": "0" # The Line index from the YFCC-100M dataset
},
....
}
FFHQ Dataset
FFHQ #
Flickr Faces High Quality (FFHQ): FFHQ is a dataset of of high quality, high resolution faces taken entirely from Flickr.com, created by NVIDIA primarily for developing face synthesis GANs. FFHQ was published in 2016 and contains 70,000 total images, of which approximately only 65,000 are still active on Flickr. The dataset has contributed significantly towards the development generative neural networks used to synthesize photorealistic fake faces. The popular website ThisPersonDoesNotExist.com uses synthetic faces generated from the FFHQ dataset. Each non-existent person’s face a multi-dimensional simulation of real identity created by extrapolating through a high-dimensional visual space based all faces in the FFHQ dataset. It is likely that many sock-puppet social media accounts used for disinformation campaigns have used fake-faces generated in full or in part from the FFHQ dataset.
FFHQ is unique among other datasets using Creative Commons images because they provide a means to opt-out on their GitHub page. However, since releasing the dataset in 2016 no photos have been removed or updated. An email to NVIDIA asking whether anyone has opted out was not answered.
FFHQ is entirely comprised of Creative Commons licensed imagery. Flickr metadata and CC licensing information is provided in 267MB JSON file. The file was too large to open on a laptop and crashed Sublime text editor. You can try downloading the file and opening it on your computer https://github.com/NVlabs/ffhq-dataset, possibly in a web browser. On basic laptop, the file was not able to fully load and caused a spinning wheel in Firefox. The only reliable way to determine attribution for each photo is to write a script to parse the JSON file or use command line utilities.
Though it is certainly possible to determine the author of a photo by, for example, writing a Python script to find the JSON attribute associated with a particular photo, it is unrealistic and effectively denies creators any meaningful attribution. Most people do not write Python code nor use command-line utilities. Storing attribution in a JSON file creates a technical barrier to attribution. It is not human-accessible.
A potential major issue with the FFHQ dataset is that it includes biometric data in the form of 68-point facial landmarks and real names without informed consent of the individuals in the photo. The biometric data has been decimated and real name has been redacted from the sample below.
FFHQ Dataset Sample
# FFHQ metadata. Personally identifiable information, including real name, and biometric data, including facial landmarks, has been removed or redacted.
{
"0": {
"category": "training",
"metadata": {
"photo_url": "https://www.flickr.com/photos/frumkin/1133484654/",
"photo_title": "DSCF0899.JPG",
"author": "[REDACTED]",
"country": "",
"license": "Attribution-NonCommercial License",
"license_url": "https://creativecommons.org/licenses/by-nc/2.0/",
"date_uploaded": "2007-08-16",
"date_crawled": "2018-10-10"
},
"image": {
"file_url": "https://drive.google.com/uc?id=1xJYS4u3p0wMmDtvUE13fOkxFaUGBoH42",
"file_path": "images1024x1024/00000/00000.png",
"file_size": 1488194,
"file_md5": "ddeaeea6ce59569643715759d537fd1b",
"pixel_size": [
1024,
1024
],
"pixel_md5": "47238b44dfb87644460cbdcc4607e289",
"face_landmarks": [
[
131.62,
453.8
],
...
]
},
"thumbnail": {
"file_url": "https://drive.google.com/uc?id=1fUMlLrNuh5NdcnMsOpSJpKcDfYLG6_7E",
"file_path": "thumbnails128x128/00000/00000.png",
"file_size": 29050,
"file_md5": "bd3e40b2ba20f76b55dc282907b89cd1",
"pixel_size": [
128,
128
],
"pixel_md5": "38d7e93eb9a796d0e65f8c64de8ba161"
},
"in_the_wild": {
"file_url": "https://drive.google.com/uc?id=1yT9RlvypPefGnREEbuHLE6zDXEQofw-m",
"file_path": "in-the-wild-images/00000/00000.png",
"file_size": 3991569,
"file_md5": "1dc0287e73e485efb0516a80ce9d42b4",
"pixel_size": [
2016,
1512
],
"pixel_md5": "86b3470c42e33235d76b979161fb2327",
"face_rect": [
667,
...
],
"face_landmarks": [
[
562.5,
697.5
],
...
],
"face_quad": [
[
371.32,
144.47
],
...
]
}
},
...
FFHQ was subsequently used to create FFHQ-Aging, a dataset of faces derived from FFHQ used for age and gender. Development of FFHQ-Aging was supported by Futurewei Technologies, the U.S. research arm of Huawei, implying commercially-aligned research. Like FFHQ, the FFHQ-Aging dataset is provided to anyone on GitHub at
https://github.com/royorel/FFHQ-Aging-Dataset. The dataset includes the file ffhq_aging_labels.csv. FFHQ-Aging inherits the same license distribution as A sample if shown below:
FFHQ-Aging Dataset Sample
image_number,age_group,age_group_confidence,gender,gender_confidence,head_pitch,head_roll,head_yaw,left_eye_occluded,right_eye_occluded,glasses
0,0-2,1,male,1,4.644246,2.1799846,-9.359347,0,0.007,None
...
FFHQ Image License Distribution
Based on metadata provided by Flickr API in 2020.
FFHQ Image Rights Distribution
Based on metadata provided by Flickr API in 2020.
FFHQ Image Country Distribution
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
FFHQ Image Tag Distribution
Based on user-supplied tags in metadata provided by Flickr API in 2020.
GeoFaces Dataset
GeoFaces #
GeoFaces is a dataset of photos used for ethnicity estimation. The dataset was published in 2014 and contains 3,142,810 total images. Exposing.ai located 2,653,081 original photos from Flickr used to build GeoFaces. The dataset has been used in at least 3 projects spanning 1 country.
GeoFaces Image License Distribution
Based on metadata provided by Flickr API in 2020.
GeoFaces Image Rights Distribution
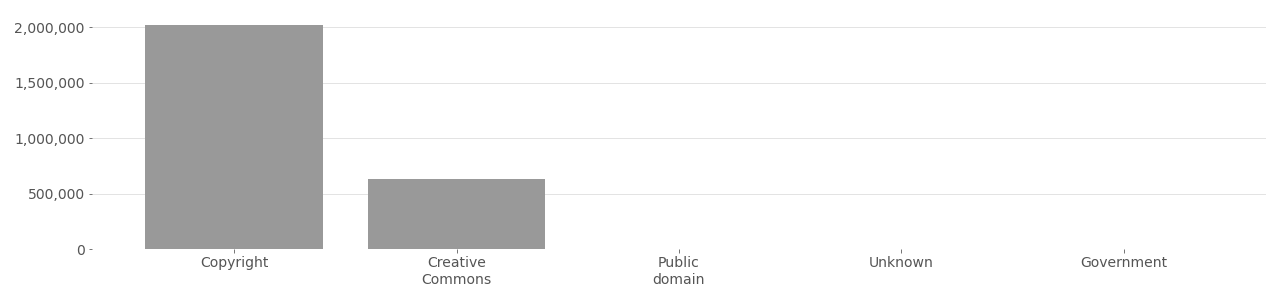
Based on metadata provided by Flickr API in 2020.
GeoFaces Image Country Distribution
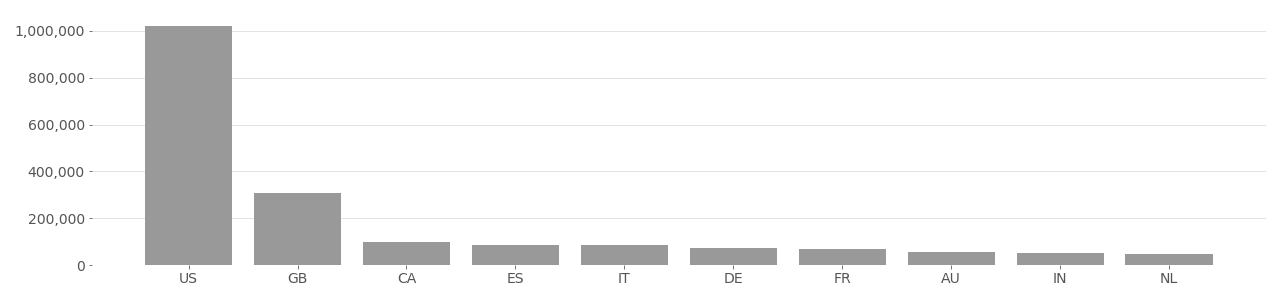
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
GeoFaces Image Tag Distribution
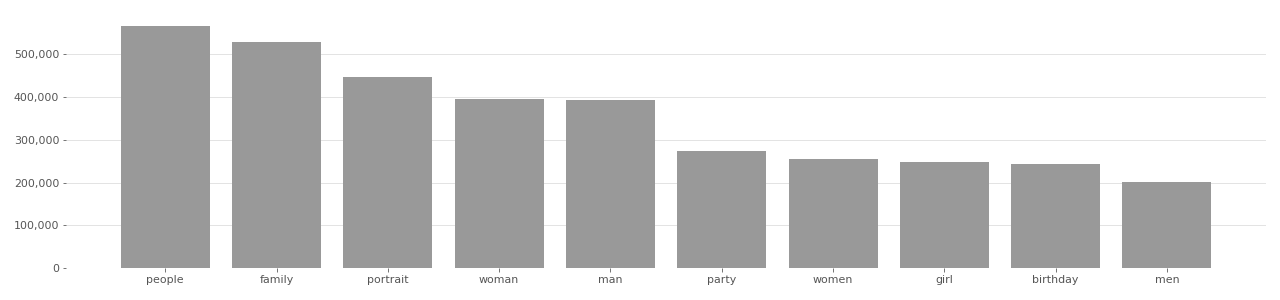
Based on user-supplied tags in metadata provided by Flickr API in 2020.
Google FEC Dataset
Google FEC #
Google Facial Expression Classification (FEC): The FEC dataset includes a total of approximately 290,000 images, of which at least 87,000 are from Flickr. The dataset is used for developing facial emotion analysis and facial search (by emotion) software. According to the authors, one of the main applications of this technology is for “expression-based image retrieval by using nearest neighbor search in the expression embedding space.”[^Vemulapalli2019ACE] Their paper, “A Compact Embedding for Facial Expression Similarity” situates the FEC dataset within the context of larger facial recognition datasets including MS-Celeb-1M and MegaFace.
FEC is used less than other similar datasets and does not use only CC images, but included to provide an example of how corporation worth over $300 billion still relies on Flickr a valuable source of training data, but with disregard for the minimal Creative Commons license requirements. The Google FEC dataset does not provide any licensing information nor metadata, only the direct image/jpg URL. FEC violates CC by not providing required CC license information for attribution and possibly by using non-commercial images for commercial application.
Although the Google FEC dataset has not been cited or abused nearly as much as MegaFace or MS-Celeb-1M it is still notable because the dataset includes 87,517 confirmed images taken from Flickr and used for the purpose of biometric analysis. Among the 87,517 total unique Flickr photos in Google FEC, there were 45,382 unique Flickr account holders (users). The data is searchable on exposing.ai/search.
The method used to create the Google FEC dataset follows a long and problematic practice of downloading images “in the wild” by ignoring license requirements and biometric laws (e.g. BIPA) that protect against this. In Illinois, the BIPA regulation prohibits any company from selling or otherwise profiting from one’s biometric information. In the FEC dataset, that biometric information is quantified as expression data, which is then used for face search. The reserach paper states the eventual intentions are for developing “products”.
The following emotion labels were conceived by the authors and used to label the 87,000+ images in the FEC dataset: Amusement, Anger, Awe, Boredom, Concentration, Confusion, Contemplation, Contempt, Contentment, Desire, Disappointment, Disgust, Distress, Doubt, Ecstasy, Elation, Embarrassment, Fear, Interest, Love, Neutral, Pain, Pride, Realization, Relief, Sadness, Shame, Surprise, Sympathy, Triumph.
The dataset is available to download without restriction at https://research.google/tools/datasets/google-facial-expression/. The data is limited to a CSV file with the URL of each Flickr photo containing the faces. The bounding boxes of each face are provided in the CSV file according to the following details:
Each line in the CSV files has the following entries:
- URL of image1 (string)
- Top-left column of the face bounding box in image1 normalized by width (float)
- Bottom-right column of the face bounding box in image1 normalized by width (float)
- Top-left row of the face bounding box in image1 normalized by height (float)
- Bottom-right row of the face bounding box in image1 normalized by height (float)
- URL of image2 (string)
- Top-left column of the face bounding box in image2 normalized by width (float)
- Bottom-right column of the face bounding box in image2 normalized by width (float)
- Top-left row of the face bounding box in image2 normalized by height (float)
- Bottom-right row of the face bounding box in image2 normalized by height (float)
- URL of image3 (string)
- Top-left column of the face bounding box in image3 normalized by width (float)
- Bottom-right column of the face bounding box in image3 normalized by width (float)
- Top-left row of the face bounding box in image3 normalized by height (float)
- Bottom-right row of the face bounding box in image3 normalized by height (float)
- Triplet_type (string) - A string indicating the variation of expressions in the triplet.
- Annotator1_id (string) - This is just a string of random numbers that can be used to
search for all the samples in the dataset annotated by a particular annotator.
- Annotation1 (integer)
- Annotator2_id (string)
- Annotation2 (integer)
Google FEC mentions the possibility of option out, but this is not a reasonable response to having your biometric data used in a commercial research data since virtually no one is aware of the Google FEC dataset. However, if think your photo might be included (you can search on on exposing.ai/search) you can email the researchers Raviteja Vemulapalli or Aseem Agarwala to request removal. Their emails are listed in the research paper at https://arxiv.org/abs/1811.11283.
Google FEC Image License Distribution
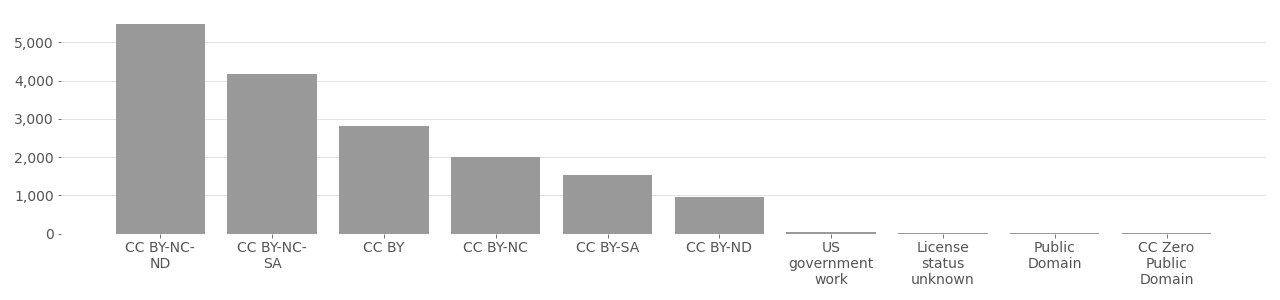
Based on metadata provided by Flickr API in 2020.
Google FEC Image Rights Distribution
Based on metadata provided by Flickr API in 2020.
Google FEC Image Country Distribution
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
Google FEC Image Tag Distribution
Based on user-supplied tags in metadata provided by Flickr API in 2020.
# Example data from the Google FEC dataset (a CSV file). The biometric data in this example has been decimated and altered
"http://farm4.staticflickr.com/3679/12137399835_d9075d3194_b.jpg",0.253125,0.68873,0.059019,0.307357,"http://farm4.staticflickr.com/3372/5791826985_e285030df5_b.jpg",0.523734,0.175633,0.455660,0.119811,"http://farm3.staticflickr.com/2712/
IBM DiF Dataset
IBM DiF #
IBM Diversity in Faces (DiF): IBM DiF is a dataset that includes “annotations of one million publicly available face images.”[^Merler2019DiversityIF] The dataset was created in 2019 to address existing biases in overwhelmingly light-skinned and male-dominated facial datasets. IBM believed that the dataset “will encourage deeper researcher on this important topic and accelerate efforts towards creating more fair and accurate face recognition systems.”[^Merler2019DiversityIF]
However, the dataset caused a fierce backlash after it became widely known through an article published on NBC News. IBM is now being sued in a class action lawsuit led by a photographer whose photos and biometrics were used without consent. He is seeking damages of $5,000 for each intentional violation of the Illinois Biometric Information Privacy Act, or $1,000 for each negligent violation, for everyone affected. The lawsuit aims to represent all Illinois citizens whose biometric data was used in the dataset. Exposing.ai has made available a portion of the IBM DiF dataset metadata on https://exposing.ai/search. Use your Flickr username, NSID, photo URL, or #hashtag to check if your images were used.
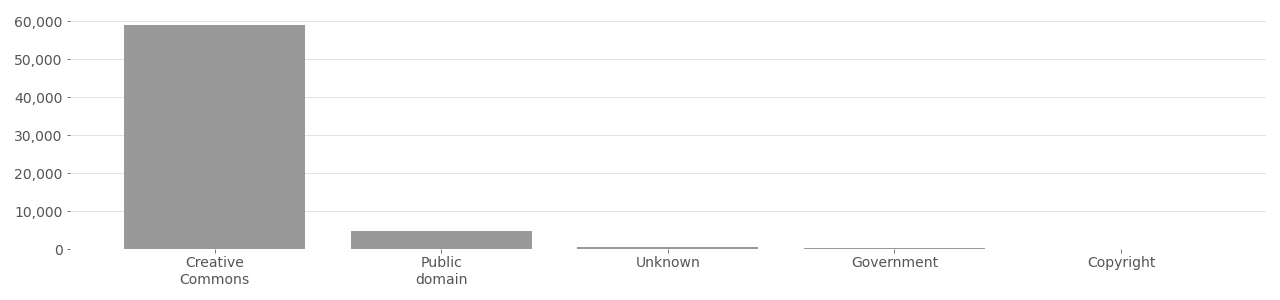
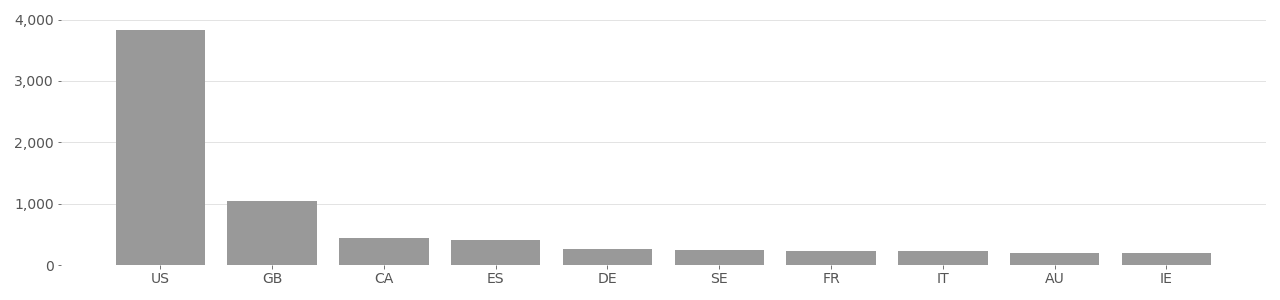
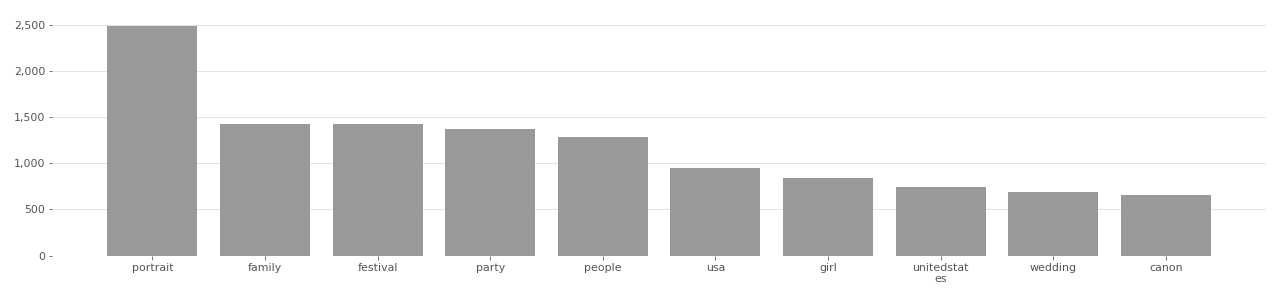
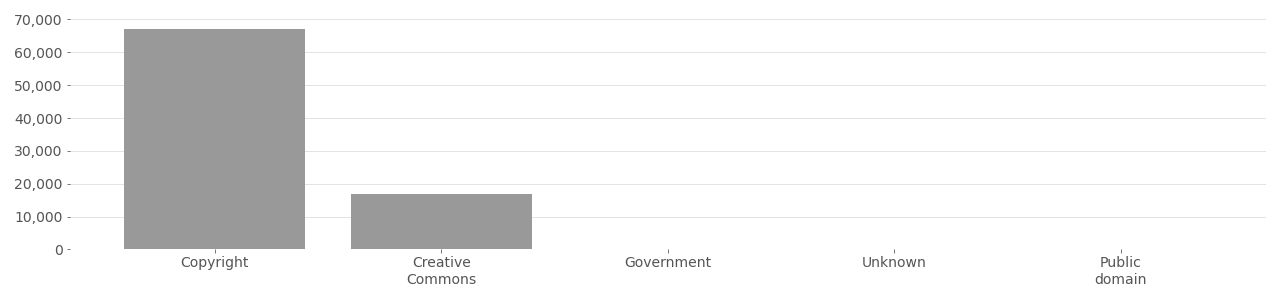
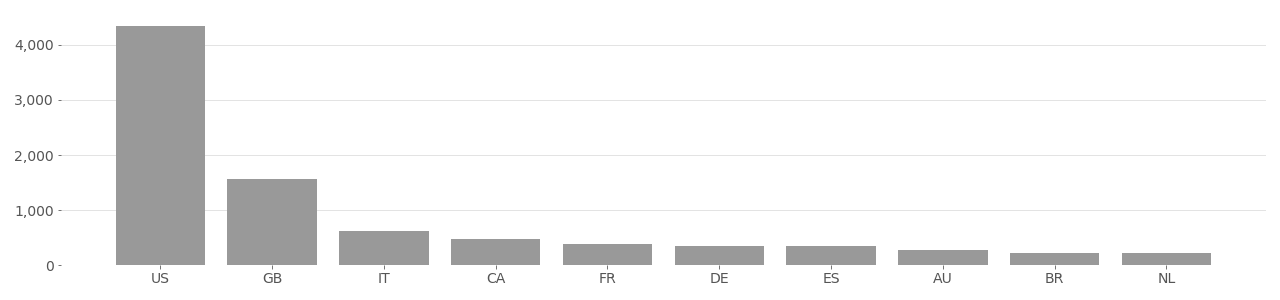
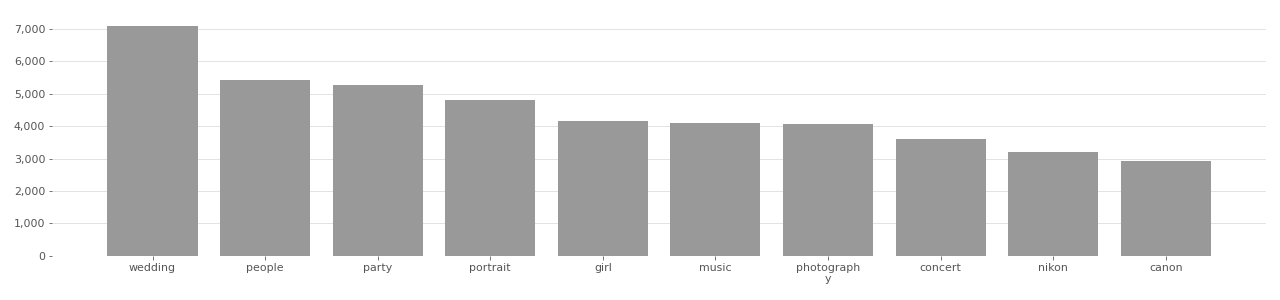
The IBM DiF dataset originates from the YFCC100M dataset, and uses only Creative Commons licensed face photos. According to the authors of the IBM DiF dataset, they “proceeded with the download [of the face image] only if the license type was Creative Commons.”[^Merler2019DiversityIF] Images that did not use a Creative Commons license were not used. An analysis of the top image tags in IBM DiF (see charts below) shows that “party”, “family”, “wedding”, and “friends” are among the top 10 most used tags in the dataset.
Following the publication of the NBC story in March 2019, then president of Creative Commons Ryan Merkley addressed the situation by explaining that even though some may disagree, “fair use allows all types of content to be used freely.” Creative Commons later published a FAQ clarifying that images may be used in machine learning datasets as long as the license conditions are respected. “Where a CC-licensed work is distributed as part of a database or dataset, and assuming copyright (or in the European Union, copyright or sui generis database rights) is triggered, then the license conditions must be respected. This means providing the required attribution information in a way that is reasonable under the circumstances. Our licenses allow for some flexibility, and in some cases that may be as simple as providing a link to the website where the relevant attribution information is provided. Visit our marking practices page for more information.”
The IBM DiF dataset includes thousands of images licensed using the CC-BY attribution requirement (see charts below). Due to obtaining only a partial sample of IBM DiF dataset, it is not yet certain what metadata was or wasn’t provided, except that most required attribution and restricted commercial use.
IBM DiF Image License Distribution
Based on metadata provided by Flickr API in 2020.
FFHQ Image Rights Distribution

Based on metadata provided by Flickr API in 2020.
FFHQ Image Country Distribution
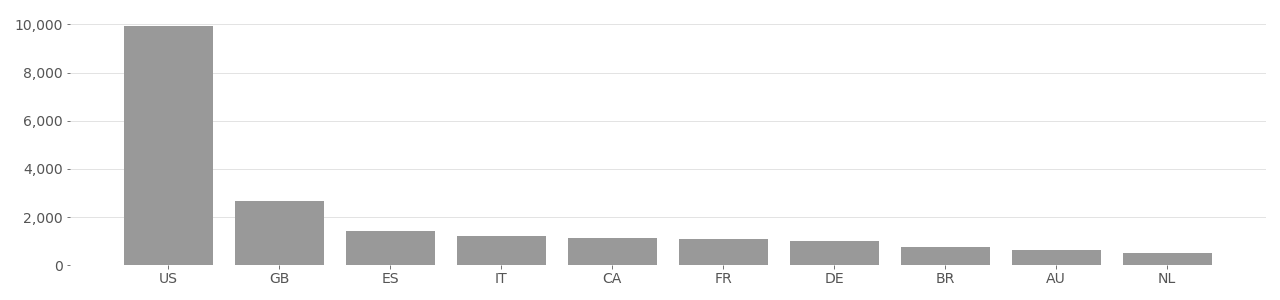
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
FFHQ Image Tag Distribution
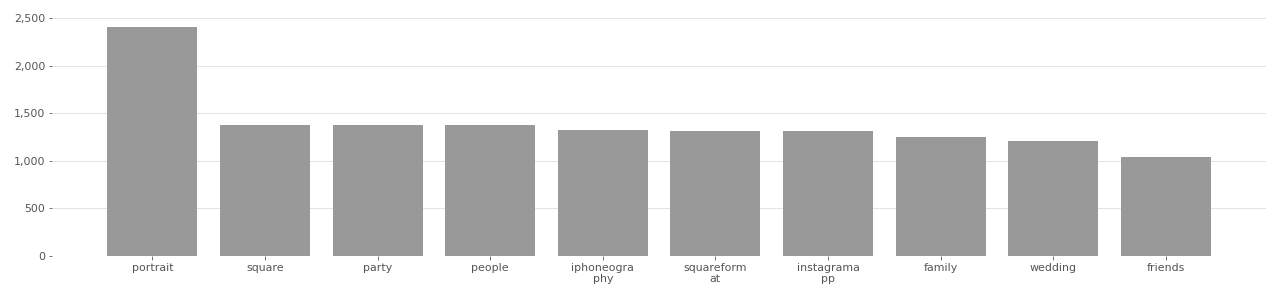
Based on user-supplied tags in metadata provided by Flickr API in 2020.
IJB-C Dataset
IJB-C #
IARPA Janus Benchmark C (IJB_C) Dataset: The IJB-C dataset was developed with the explicit intention to assist US intelligence agency analysts by providing a benchmark dataset to evaluate the effectiveness of face recognition technologies. The dataset comprises images from Flickr, Wikimedia, and YouTube all of which were selected because of their Creative Commons license. Only images with Creative Commons licenses were selected for this dataset. The dataset was published in 2017 and contains 21,294 total images, including 5,757 original photos from Flickr.
The IJB-C dataset includes both images and full names. The name list includes 3,531 individuals. Many are activists, artists, journalists, foreign politicians, and public speakers. Unlike other similar datasets that used the Internet Movie Database as a starting point for gathering names of actors and celebrities, the IJB-C dataset authors instead relied on “YouTube users who upload well-labeled, person-centric videos, such as the World Economic Forum and the International University Sports Federation were also identified”. These sources were identified as ideal candidates for the IJB-C dataset.[^Whitelam2017IARPAJB]
This approach resulted in casting a wide net gathering many individuals who frequently give lectures to online audiences, or participate in conferences that were later posted to YouTube. Using videos from YouTube for face recognition is a clear violation of their policy, which Google clarified in a November 2020 memo and recently re-clarified in a May 2021 memo further emphasizing in bold text that using data from YouTube for face recognition is a violation of their Terms of Service However, thousands of faces from over 11,000 YouTube videos are included in the IJB-C face recognition benchmarking dataset, along with full names for each person because they used Creative Commons licenses. In total the dataset includes face data from 11,799 YouTube videos and 21,294 photos from Wikimedia or Flickr. According to the dataset authors, all the “images were scraped from Google and Wikimedia Commons, and Creative Commons videos were scraped from YouTube.”[^Whitelam2017IARPAJB]
IJB-C Image License Distribution
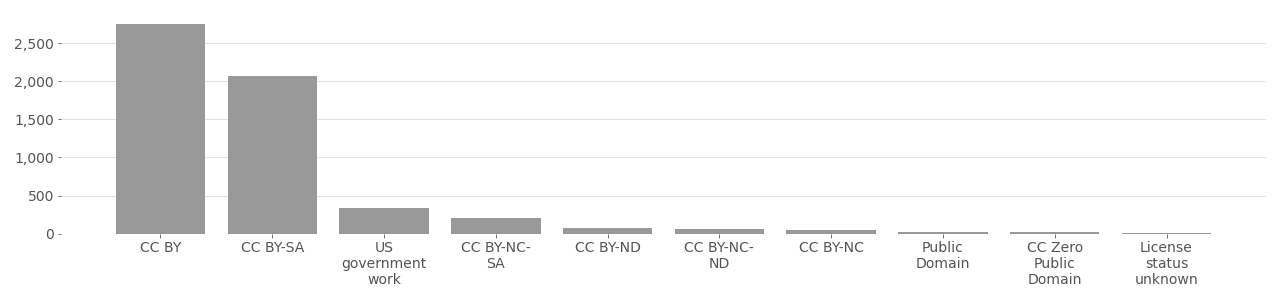
Based on metadata provided by Flickr API in 2020.
IJB-C Image Rights Distribution
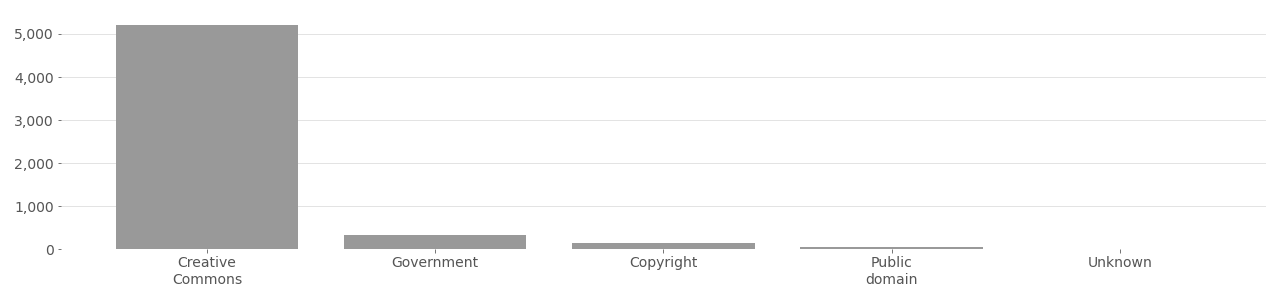
Based on metadata provided by Flickr API in 2020.
IJB-C Image Country Distribution
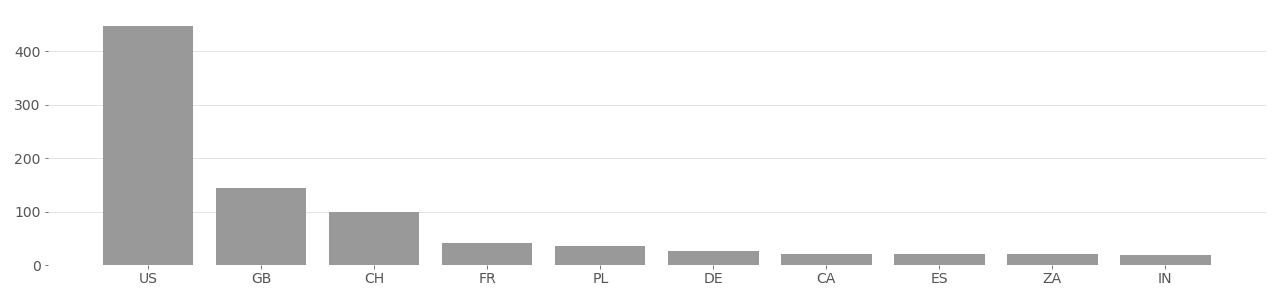
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
IJB-C Image Tag Distribution
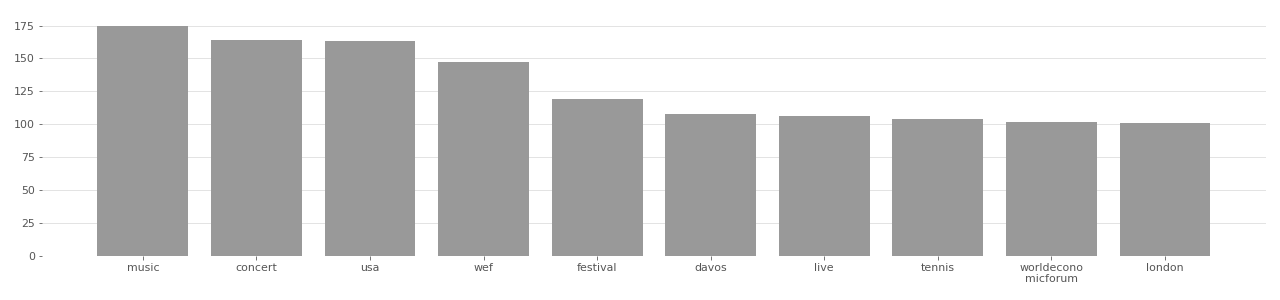
Based on user-supplied tags in metadata provided by Flickr API in 2020.
# Unaltered data from IJB-C dataset file "cs3_media.csv"
Media ID,Media URL,CC License,Source URL,Attribution
frames/10001.png,http://www.youtube.com/watch?v=mbIFvrfkc_U,cc-by-3.0,http://www.youtube.com/watch?v=mbIFvrfkc_U,David Jackmanson in Moe Gippsland Australia (http://youtube.com/channel/UC81XWHb4BrWIgyGUeh1I_kg)
# Unaltered data from IJB-C dataset file "cs4_media.csv"
Media ID,Media URL,CC License,Source URL,Attribution
frames/155805.png,https://www.youtube.com/watch?v=1q1nRHuwRIE,cc-by-3.0,https://www.youtube.com/watch?v=1q1nRHuwRIE,HeavenlyPeach 천도복숭아 (https://www.youtube.com/channel/UCOyLLwRWljNYuNBy8JyNVEw)
MegaFace Dataset
MegaFace #
The MegaFace dataset was created by the University of Washington and became one of the most important face recognition benchmark, research, and training datasets for the purpose of face recognition. It used by hundreds if not thousands of companies, and includes 100% Flickr images. All images are derived from the larger predecessor YFCC100M dataset (as as DiF). To date, there has not yet been a lawsuit against the creators of the MegaFace dataset, but it is likely that there could be. MegaFace uses images from Flickr with CC-BY requirement but provides no attribution for any photo. It includes over 3.7 million photos from Flickr.
MegaFace: MegaFace is a large-scale public face recognition training dataset that serves as one of the most important benchmarks for commercial face recognition vendors. It includes 4,753,320 faces of 672,057 identities from 3,311,471 photos downloaded from 48,383 Flickr users’ photo albums. All photos used a Creative Commons licenses, and most were not licensed for commercial use.
The dataset was used to advance facial recognition technologies around the world by companies including Alibaba, Amazon, Google, CyberLink, IntelliVision, N-TechLab (FindFace.pro), Mitsubishi, Orion Star Technology, Philips, Samsung [^Nech2017LevelPF], SenseTime, Sogou, Tencent, and Vision Semantics to name only a few. According to the press release from the University of Washington, “more than 300 research groups [were] working with MegaFace” as of 2016, including multiple law enforcement agencies.
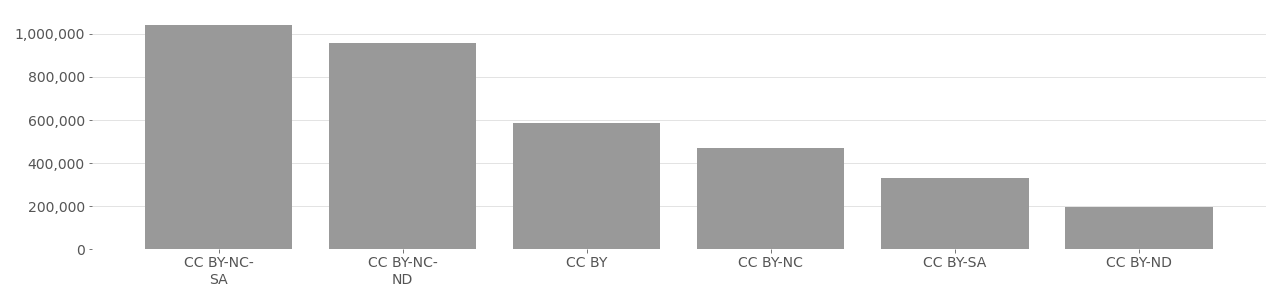
According to an analysis of the 3,311,471 MegaFace images from 48,383 Flickr accounts, 100% were from YFCC100M and used a Creative Commons license, 69% (2,284,369) prohibited commercial use, while 31% (1,027,102) permitted it. All 3,311,471 images in the MegaFace dataset legally required attribution, but no attribution was provided by the MegaFace dataset. This amounts to 3,311,471 violations of Creative Commons licenses. It’s still unclear if using the images for commercial face recognition is in violation of the CC-NC restriction.
The MegaFace dataset annotation files include biometric information in the form of a 68-point face landmark. An example of the annotation is provided below without biometric data. Because the dataset does not include metadata, it does not include any other personally identifiable information.
MegaFace Image License Distribution
Based on metadata provided by Flickr API in 2020.
MegaFace Image Rights Distribution

Based on metadata provided by Flickr API in 2020.
MegaFace Image Country Distribution
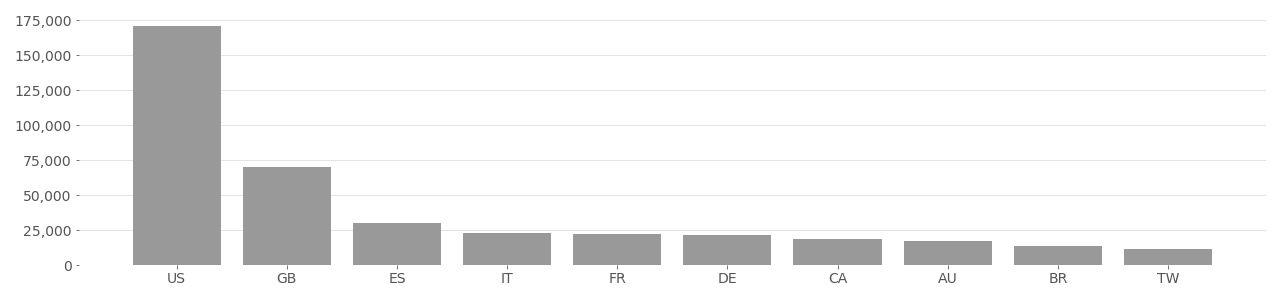
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
MegaFace Image Tag Distribution
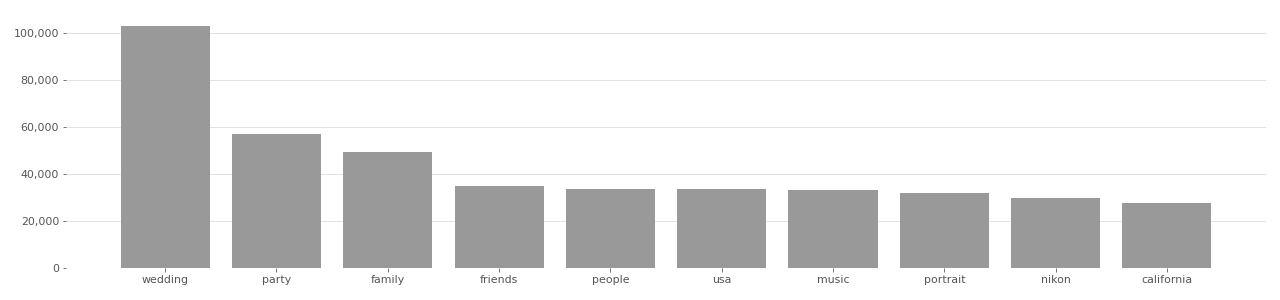
Based on user-supplied tags in metadata provided by Flickr API in 2020.
# MegaFace
{
"box":
{
"top": 1121,
"right": ...,
"left": ...,
"bottom": ...
},
"full_img_url": "https://farm6.staticflickr.com/####/#####_#####_o.jpg",
"exp_bb":
{
"top": 1055,
"right": ...,
"left": ...,
"bottom": ...
},
"landmarks": "[(7, 12), ...]"
}
PIPA Dataset
PIPA #
People in Photo Albums (PIPA): PIPA is a dataset of photos from Flickr used for face recognition. The dataset was published in 2015 and contains 60,000 face images of about 2,000 individuals, of which 32,518 photos were taken from Flickr.com. All images use a Creative Commons license and several thousand are no longer available on Flickr.
According to the dataset authors, PIPA was designed to help recognize peoples’ identities in photo albums in an unconstrained setting. But face recognition has applications far beyond personal photo album processing. And sharing a dataset of face images for building face analysis tools contributes to unexpected applications. For example, in 2018 researchers from a military research university in China used the PIPA dataset for their research on “ Understanding Humans in Crowded Scenes”. The dataset was also used by researchers affiliated with the surveillance company SenseTime and the American surveillance company Facebook.
As of January 2020, Berkeley is not longer distributing the dataset though Max Planck Institut in Germany still provides it for free and unrestricted download at https://www.mpi-inf.mpg.de/departments/computer-vision-and-machine-learning/research/people-detection-pose-estimation-and-tracking/person-recognition-in-personal-photo-collections.
The charts below show an analysis of the most frequent image tags that were used for the Flickr images in the PIPA dataset. Thousands of images include tags for #DoD (Department of Defense) and #Military.
PIPA Image License Distribution
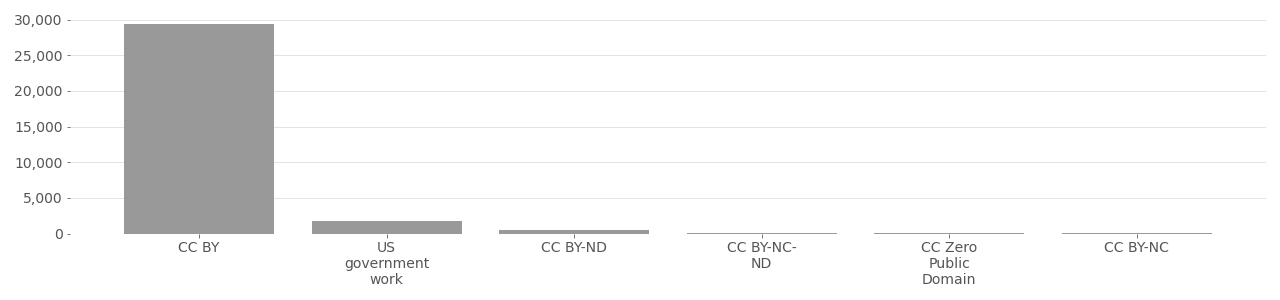
Based on metadata provided by Flickr API in 2020.
PIPA Image Rights Distribution
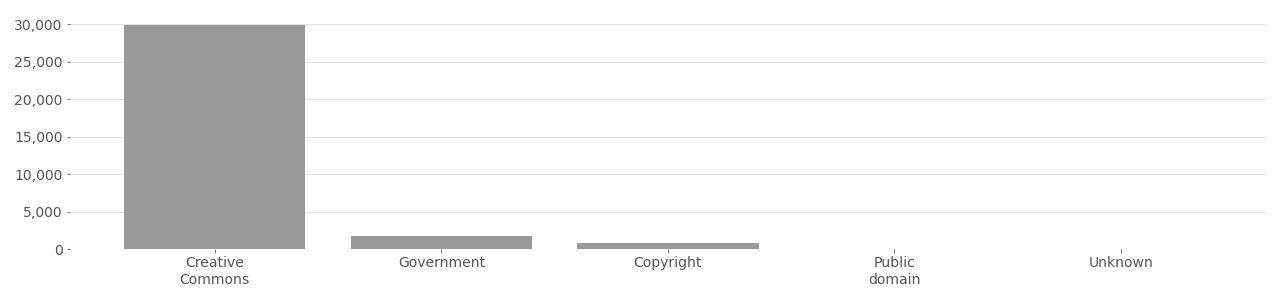
Based on metadata provided by Flickr API in 2020.
PIPA Image Country Distribution
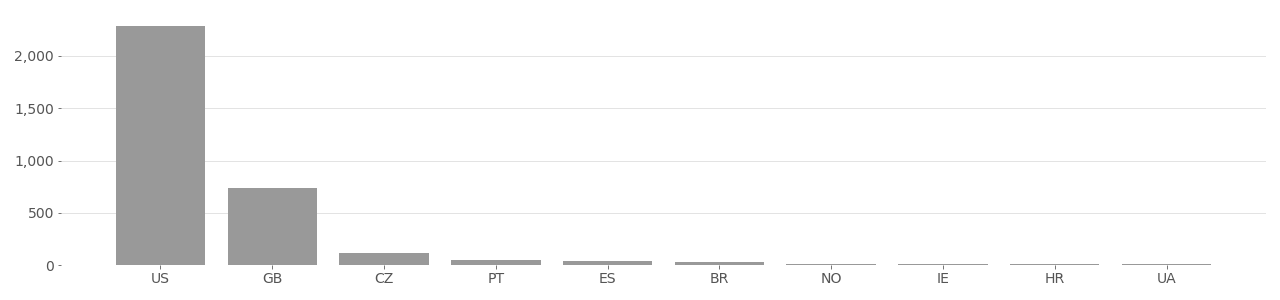
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
PIPA Image Tag Distribution
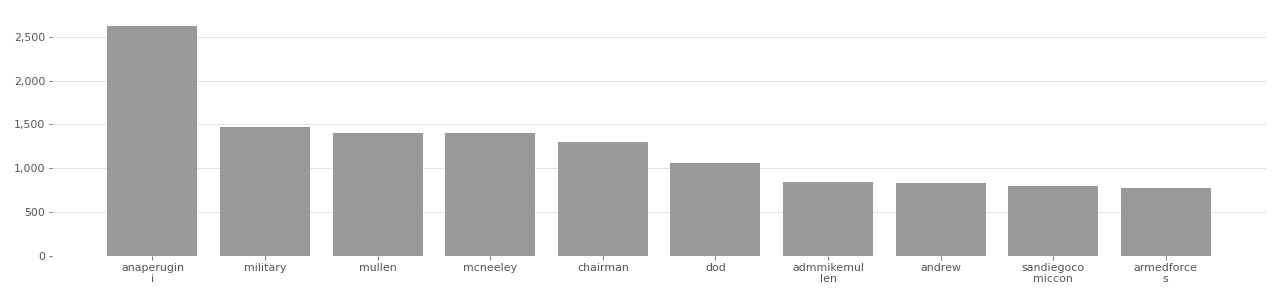
Based on user-supplied tags in metadata provided by Flickr API in 2020.
The annotations are in the file data.mat and also in the text file index.txt, which has the following format:
# example data from PIPA with biometric data decimated
photoset_id, photo_id, xmin, ymin, width, height, identity_id, subset_id
72157607317745768, 1808093328, 277, ###, 218, ###, 1, 1
The Creative Commons data is provided in the following format:
# corresponding license data provided by PIPA
Copyright Estonian Foreign Ministry Attribution License
https://creativecommons.org/licenses/by/2.0/
https://www.flickr.com/photos/estonian-foreign-ministry/1808093328
Who Goes There Dataset
Who Goes There #
Who Goes There is a dataset of face images from Flickr used for estimating ancestral origin. It was published in 2016, unpublished in 2022, and includes 2,106,478 images. The dataset was publicly available to anyone and included face data in the form of a 256x256 face chip, along with metadata from Flickr including real names, and additional biometric dataset including a 68-point face landmark. All images in Who Goes There are from the superset YFC100M. According to the dataset authors, they relied on the 49 million images in YFCC100M that included geographic information to build their dataset of 2.1M face images.[^bessinger2016who.pdf] The dataset is provided in hdf5 format and includes the following attributes:
keys_all = ['accuracy', 'admin1', 'admin2', 'age', 'capture_device', 'city',
'content_length', 'country_code', 'date_taken', 'date_uploaded',
'description', 'face', 'face_bounds', 'face_key', 'face_landmarks_f',
'face_landmarks_o', 'gender', 'im_download_url', 'im_extension_original',
'im_farm_id', 'im_id', 'im_page_url', 'im_secret', 'im_secret_original',
'im_server_id', 'index', 'latitude', 'license_name', 'license_url', 'longitude',
'machine_tags', 'title', 'user_nickname', 'user_nsid', 'user_tags']
The authors describe using a 68 point face landmark
Who Goes There Image License Distribution
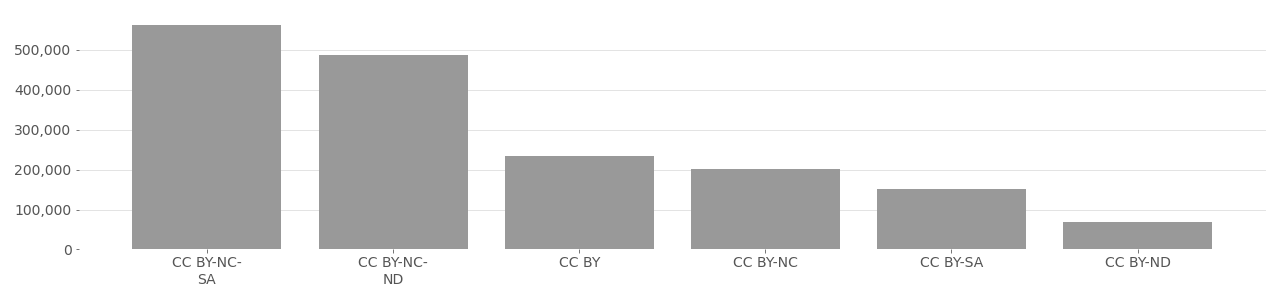
Based on metadata provided by Flickr API in 2020.
Who Goes There Image Rights Distribution

Based on metadata provided by Flickr API in 2020.
Who Goes There Image Country Distribution
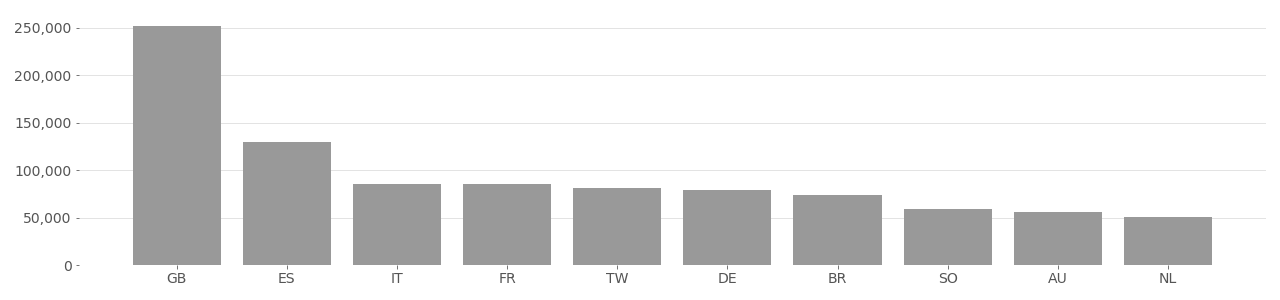
Based on user-supplied image geolocation in metadata provided by Flickr API in 2020.
Who Goes There Image Tag Distribution
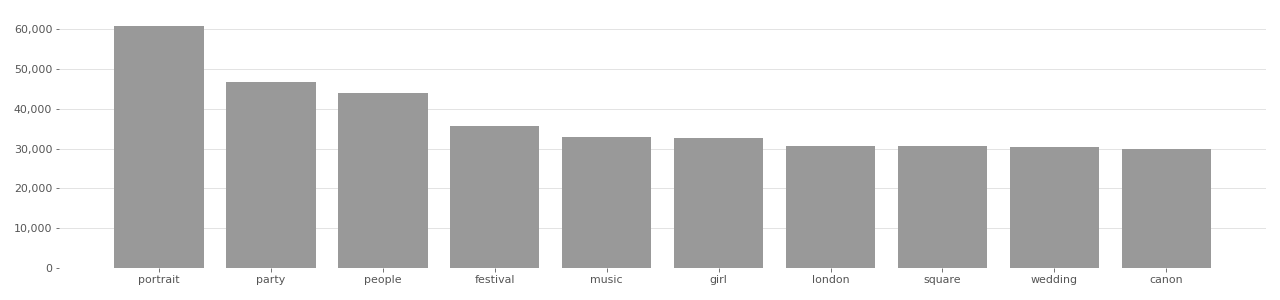
Based on user-supplied tags in metadata provided by Flickr API in 2020.
YFCC100M Dataset
YFCC100M #
Yahoo! Flickr Creative Commons 100M (YFCC100M): YFCC100M is the largest dataset of Flickr images used for computer vision and AI applications. The dataset exists as a text file that includes 99,171,688 image URLs and Flickr metadata for each photo. YFCC1000M is typically described as containing 100 million images, but actually includes approximately 800,000 CC videos. YFCC100M served as the foundation for many smaller datasets including IBM DiF,MegaFace, DiveFace, FairFace, and FDF. YFCC100M set an important precedent in mis/communicating the requirements of the Creative Commons licensed imagery and gave the false impression that all images were “free and legal to use”, leading other developers to assume that since an image was included in YFCC100M it was legal permissible to use it for any other dataset. All images in YFCC100M are from Flickr and all use a Creative Commons license.
YFCC100M Image License Distribution
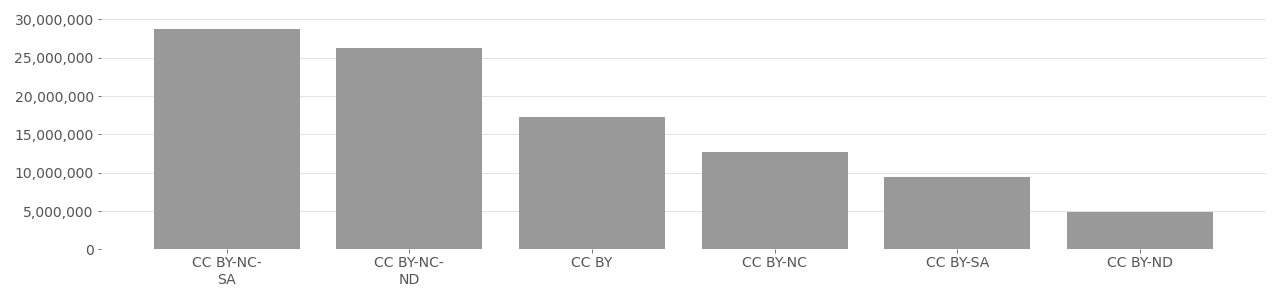
Based on metadata provided by Flickr API in 2020.
YFCC100M Image Rights Distribution

Based on metadata provided by Flickr API in 2020.
YFCC100M Image Tag Distribution
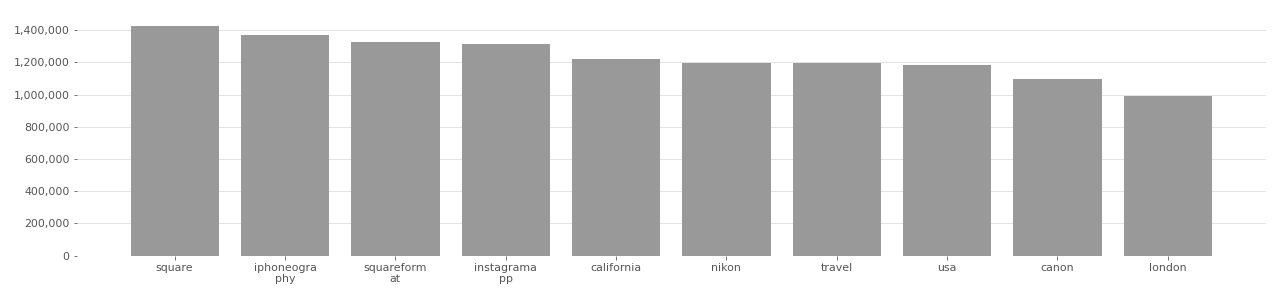
Based on user-supplied tags in metadata provided by Flickr API in 2020.
Issues #
Among the most common issues related to the use of CC images in datasets are related to the attribution and commercial clauses. The issues below highlight 4 issues related to the commercial and attribution issues, and how biometric data and attribution issues intersect each other.
Issue 1: Potential Commercial Use of Non-Commercial Images
Issue 1: Potential Commercial Use of Non-Commercial (CC-NC) Images #
Datasets affected: COCO, FFHQ, MegaFace, YFCC100M
Issues of potential commercial use arise when CC images were used by commercial organizations towards the development of products or new technology. Often this overlaps with corporate funded academic research.
For example, MegaFace was created 2015 by researchers at the University of Washington to “evaluate and encourage development of face recognition algorithms at scale”. The dataset was funded by Samsung, Google, and Intel. All companies have developed, sold, and/or profited from face recognition technologies. At the time MegaFace was published it was the largest publicly available face recognition dataset and included an expanding number of face photos that reached over 4 million in second version published in 2016. More precisely, MegaFace included 4,753,320 face images of 672,057 identities from 3,311,471 photos downloaded from 48,383 Flickr users’ photo albums. The authors explain how they leveraged “the recently released database of Flickr Creative Commons photos, from which we extracted 1 million faces (randomly sampling the full 100M photo collection),”[^megaface_benchmark] referring to YFCC100M. All photos in MegaFace are derived from YFCC100M, and therefore include a Creative Commons licenses, but most were not licensed for commercial use. According to an analysis of metadata associated with each photo in MegaFace obtained through the Flickr API in 2020, 69% (2,284,369) of the MegaFaces images used a CC licensed that prohibited commercial use (CC-NC), while only 31% (1,027,102) allowed it. But all 3,311,471 images required some form of attribution, of which none was provided by the MegaFace dataset nor any of the research projects that used it (see Issue 3 for more information about missing attribution).
The commercial use of MegaFace is made clear through a FOIA document obtained by New York Times reporter Kashmir Hill. The document shows that thousands of companies, organizations, and researchers requested to download and use the MegaFace dataset images. The table below shows a small sample focused on commercial use. Many additional defense and law-enforcement related uses can be seen in the FOIA document. This document helps prove that the MegaFace dataset images were used commercially. In other words, companies that used MegaFace benefited commercially by using MegaFace to advance their face recognition related technologies. Yet 2,284,369 did not allow commercial use.
The following figures show the distribution of CC licenses and the companies that reportedly downloaded the data for use in commercial or face recognition:

MegaFace dataset Creative Commons license distribution
MegaFace Dataset Usage: Commercial Organizations #
| Group Name | Affiliation | Email Domain | Date | Valuation |
|---|---|---|---|---|
| Alibaba_ATL | Alibaba Inc. | alibaba-inc.com | 2018-05-15 | $313B |
| SOPHON-28 | Bitmain | bitmain.com | 2018-08-21 | |
| ByteDance | ByteDance | bytedance.com | 2018-01-23 | $250B |
| EverAI | [REDACTED]@ever.ai | EverAI | 2018-01-16 | |
| fb.com | 2019-08-07 | $647B | ||
| Google Research | Google Inc | google.com | 2018-03-08 | $1.8T |
| AIlab | Huawei Technologies Co., Ltd | huawei.com | 2018-10-10 | |
| AU/Vic BDM | Hikvision | hikvision.com | 2018-08-20 | $67B |
| Intel Corp | Intel Corp | intel.com | 2019-02-03 | $196B |
| IBM TJ Watson | IBM Research | us.ibm.com | 2017-02-28 | $123B |
| RecPlus | Megvii Inc. | megvii.com | 2017-05-01 | |
| FACENEXT | Microsoft | microsoft.com | 2017-09-10 | $2.2T |
| SAE | NVIDIA | nvidia.com | 2019-02-20 | $614B |
| PSL | Panasonic R&D(PRDCSG) | sg.panasonic.com | 2017-08-17 | $24.3B |
| SR | Samsung Electronic | samsung.com | 2018-10-10 | $413B |
| SenseTime | SenseTime | sensenets.com | 2018-01-31 | |
| Tencent Youtu | shanghai,China | tencent.com | 2018-12-16 | $582B |
| Smartcheckr Corp | Smartcheckr LLC | smartcheckr.com | 2018-03-18 |
Market valuation according to companiesmarketcap.com data on Feb. 7, 2022.
MegaFace Download Requests FOIAProving commercial use of image training data is still a gray-ish area although a recent cases against photo storage app in the US set an important legal precedent that could echo through the face recognition and computer vision industry, eventually posing problems for any commercial product developed using images from MegaFace.
In 2021, The Federal Trade Commission (FTC) settled a case against California-based Everalbum, Inc. (now Paravision AI) after a 2019 investigation from NBC News found that consumers were deceived by Everalbum when their photos were used as biometric data in facial recognition system. The settlement required Everalbum to delete all photos and videos from inactive accounts along with their face embeddings and “any facial recognition models or algorithms developed with Ever users’ photos or videos.[^ftc_everalbum] While the settlement against Everalbum points towards a clearer perspective that business must first obtain consent for using consumer data in a commercial AI model, it leaves open many questions about what can be taken from the “open web” and used in commercial AI models. Coincidentally, Everalbum’s AI division (Ever AI) is among the list of organizations that requested to download and use the MegaFace dataset for development of face recognition technology (see chart above).
Another example of potential commercial use is the COCO (or MS-COCO) dataset. It includes over 300,000 Creative Commons images taken from Flickr.com and is used as a foundational computer vision dataset, meaning that many production (final product) computer vision models may utilize an object detection model pre-trained on the COCO dataset.
The COCO dataset is so popular it even has its own consortium called the COCO Consortium. The original paper associated with the dataset “Microsoft COCO: Common Objects in Context” has been cited in nearly 18,000 research papers making it among the most ever cited computer vision research papers. Among these citations is the 2016 research paper “ Deep Residual Learning for Image Recognition” (by Microsoft) that relied on COCO for its landmark discoveries in deep learning, earning an estimated 85,376 citations and 17,886 highly influential citations. Search results for papers that use COCO yield over 848,000 results on SemanticScholar. Search results for patent publications that mention “COCO dataset” on Google Scholar yield over 570 results.
While it is clear that COCO has generated tremendous commercial value, especially to Microsoft, the dataset’s parent company, does this violate Creative Commons Non-Commercial clause? According to CC:
“NonCommercial means not primarily intended for or directed towards commercial advantage or monetary compensation.” source
Is Microsoft’s COCO primarily intended for or directed towards commercial advantage or monetary compensation? Since the dataset is freely offered, the latter clause does not apply. But possibly the former is applicable. The first sentence of the COCO paper states the goal is to advance technological capabilities: “We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding”. Since Microsoft has used COCO towards the goal of advancing their capabilities it would seems that their use of COCO could be considered commercial. A 2018 patent awarded to Microsoft Technology Licensing LLC Detecting objects in crowds using geometric context includes claims that their “models are pre-trained on the COCO dataset” and that “two rounds of inference were run with the pre-trained COCO model.” Dozens more patents by other companies include reference to COCO and sometimes actual CC photos in the patent publication.
Another example of commercial use could be the FFHQ dataset created by NVIDIA. The dataset distribution page solicits business inquires related to the application of technology developed using the FFHQ dataset though does not provide clear details about whether any model is being deployed that is trained on the FFHQ dataset. Though the intentions are clear: NVIDIA used CC images to build the FFHQ dataset in order to advanced their technological capabilities and products.
Issue 2: Non-Consensual Use of Biometric Data
Issue 2: Non-Consensual Use of Biometric Data #
Datasets affected: IBM DiF, MegaFace, FDF, Who Goes There
Many images in MegaFace include biometric data in the form of a 68-point facial landmark. This type of biometric data was recently referenced in the ongoing class action lawsuit against IBM. According to a classaction.org post, “[t]he lawsuit says that in processing the photos to be used in its dataset, IBM also extracted the “pose and 68 key-points” for each image, including measurements on the distances between an individual’s eyes, ears, nose, mouth and chin and predictors for age and gender. Flickr users who uploaded photos to the platform, as well as individuals who appear in those photos, “had no idea” IBM would acquire or use the pictures for its own purposes, the suit argues.”
This same 68-point facial landmark is included and freely distributed in the MegaFace dataset without any consent or knowledge by the owner or subjects appearing in the photo. In the U.S., processing biometric data from Illinois residents without their expressed consent violates BIPA[^bipa]. It is highly likely that MegaFace dataset includes users from Illinois since both IBM DiF and MegaFace datasets both draw from YFCC100M. According to a FOIA document obtained by New York Times reporter Kashmir Hill, several thousands of organizations, including law enforcement and defense contractors, requested to use and download the MegaFace dataset including the 68-point facial landmark data, far more companies that are mentioned in the class action lawsuit against IBM for their DiF dataset. If the class action lawsuit against IBM’s DiF dataset is successful it could set an important precedent for class action lawsuits against other datasets.

An Illinois resident initiated a class-action lawsuit against IBM for using his biometric information without consent in the IBM Diversity in Faces dataset. The lawsuit is still active.
The FFHQ dataset also includes the 68-point facial landmark biometric data. Because FFHQ uses Creative Commons images that require attribution, photos in FFHQ link personally identifiable data and biometric data. This becomes a Catch-22. In the EU, GDPR considers biometric data to be a special category defined as:
“personal data resulting from specific technical processing relating to the physical, physiological or behavioral characteristics of a natural person, which allow or confirm the unique identification of that natural person, such as facial images or dactyloscopic (fingerprint) data.”
If a face dataset uses Creative Commons licensed images that require attribution (all CC images except CC0 require it), and attribution often includes real names (a class of personally identifiable information), it follows that any face dataset using CC images as biometric data would either violate CC or GDPR law. This has yet to be tested.
Additionally, the Who Goes There dataset includes a 68-point landmark and the FDF dataset includes a 7-point facial landmark. However neither Who Goes There or FDF have seen widespread commercial exploitation on the scale of MegaFace of IBM DiF.
A slightly different example of non-consensual biometric data recently occurred on the AI platform HuggingFace.co, when they provided full access to the biometric face-embeddings for all 108,501 faces in the FairFace dataset. Because the FTC case against Everalbum (Paravision AI) described face-embeddings as a type of biometric data and required that Everalbum delete this data and any AI models derived from it, it is likely that the face-embeddings on HuggingFace were also a violation. HuggingFace promptly removed the face-embeddings after being notified about it.
Issue 3: Attribution Missing
Issue 3: Attribution Missing #
Datasets affected: COCO, DiveFace, FDF, Google FEC, FairFace, MegaFace
When datasets include Creative Commons images, many make a well-intentioned effort to include attribution in a machine-readable format like JSON or XML. Though sometimes, they entirely omit it.
MegaFace, one of the most widely used face recognition datasets, includes 3.3 million photos from Flickr, all of which are require attribution. Yet not a single photo in MegaFace provides attribution.
MegaFace Image License Distribution
Based on metadata provided by Flickr API in 2020.
Full range of attributes in MegaFace metadata (no attribution):
{
"box":
{
"top": 1121,
"right": ...,
"left": ...,
"bottom": ...
},
"full_img_url": "https://farm6.staticflickr.com/####/#####_#####_o.jpg",
"exp_bb":
{
"top": 1055,
"right": ...,
"left": ...,
"bottom": ...
},
"landmarks": "[(7, 12), ...]"
}
COCO is another clear example of missing attribution. The CC licenses are indicated only as a number in the metadata file. Files are “attributed” by providing a directly link to the JPG file on Flickr. Unless it could be argued that attribution is provided in the form of the photo ID that could be used to query the Flickr API to obtain the attribution, neither dataset includes attribution.
As an example of how unrealistic that would be, consider the real photo URL https://live.staticflickr.com/895/40540001375_704cb3cbc1_c_d.jpg. Can you provide attribution for the creator?
COCO Image License Distribution
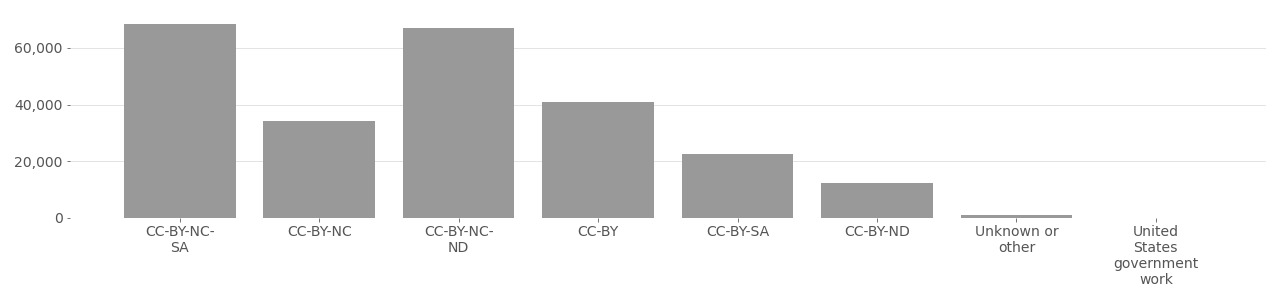
Based on metadata provided by Flickr API in 2020.
Full range of data in COCO (no attribution):
{
"license": 3,
"file_name": "000000######.jpg",
"coco_url": "http://images.cocodataset.org/train2017/000000######.jpg",
"height": 360,
"width": 640,
"date_captured": "2013-11-14 11:18:45",
"flickr_url": "http://farm9.staticflickr.com/8186/##########_##########_z.jpg",
"id": 391895
},
Likewise, the Google FEC, FairFace, DiveFace, FDF, and GeoFaces datasets all entirely lack attribution (see dataset section for additional context on licenses and metadata).
Google FEC Image License Distribution
Based on metadata provided by Flickr API in 2020.
FairFace Image License Distribution
(no metadata provided for chart)
Full range of attributes in FairFace metadata (no attribution):
file, age, gender, race, service_test
train/1.jpg, 50-59, Male, East Asian, TRUE
DiveFace Image License Distribution
Based on metadata provided by Flickr API in 2020.
Full range of attributes in DiveFace metadata (no attribution):
100016927@N02_identity_1/9469948405_7.jpg
GeoFaces Image License Distribution
Based on metadata provided by Flickr API in 2020.
Full range of attributes in GeoFace metadata (no attribution):
825510####,http://farm9.static.flickr.com/8202/##########_##########_b.jpg
Issue 4: Lack of Meaningful Attribution
Issue 4: Lack of Meaningful Attribution #
Datasets affected: FFHQ, YFCC100M, IJB-C, Who Goes There, and GeoFaces
Often datasets struggle to provide attribution in a human-accessible way because the distribute thousands of million of images. To satisfy the basic requirements of CC, dataset authors typically dump attributions in JSON or XML files. Technically, these are human-readable formats, but sometimes are so large the files can not be opened.
For example, attributions for the FFHQ dataset are provided in a 255MB JSON file that crashed a text editor when trying to open it. As an exercise in attribution-absurdity, it’s highly recommended to try opening it. Go to
https://github.com/NVlabs/ffhq-dataset, download ffhq-dataset-v2.json, then open it in your favorite editor.
The same absurdity applies to YFCC100M (a 12.5GB metadata file), the IJB-C dataset (two spreadsheets only available upon research-access request to NIST), and Who Goes There (a HDF5 format file). Only coders, approved researchers, systems administrators, or those familiar with the terminal will be able to access the attributions.
Another type of lack of attribution occurs when a dataset is integrated into a API, allowing developers to download it automatically. For example, when the “FairFace” dataset of 108,501 face photos from Flickr images was made available on HuggingFace via their dataset API it meant that developers would never have to access, download, or need to see any attribution metadata. This effectively circumvents attribution. HuggingFace removed the dataset after it was flagged on Twitter but a snapshot of how it appeared in their API is available on Wayback Machine.
According to CC, the attribution requirement is vague and easy to misunderstand:
Where a CC-licensed work is distributed as part of a database or dataset, and assuming copyright (or in the European Union, copyright or sui generis database rights) is triggered, then the license conditions must be respected. This means providing the required attribution information in a way that is reasonable under the circumstances. Our licenses allow for some flexibility, and in some cases that may be as simple as providing a link to the website where the relevant attribution information is provided. Visit our marking practices page for more information. ( source)
It’s not really clear how attribution should be provided since a dataset developer could easily argue the only reasonable way to attribute millions of photos is to store annotations in a massive metadata file, thereby making it inaccessible to most people.
Dataset Usage Analysis #
The following sections provides details about how the datasets were used, their contents, and how images were sourced. When possible sources are cited from the original research papers to provide the most factual information.
Table: How Were Images Collected?
How Were Images Collected? #
The following table describes how images were obtained according to the research paper associated with each dataset’s origin. See Appendix B for expanded descriptions of each dataset.
| Dataset | Data Acquisition Method |
|---|---|
| COCO | Flickr keyword search |
| DiveFace | Reuses images from MegaFace, a subset of YFCC100M |
| GeoFaces | “downloaded geotagged imagery from Flickr with face-related tags (e.g. face, portrait, men, family, friends)” |
| Google FEC | “generated by sampling images from a partially-labeled internal face dataset” |
| FDF | “crawled from the YFCC-100M dataset” |
| FairFace | “Images were collected from the YFCC-100M Flickr dataset and labeled with race, gender, and age groups.” |
| FFHQ | “crawled from Flickr” |
| IBM DiF | “The DiF annotations are made on faces sampled from the publicly available YFCC-100M data set of 100 million images” |
| IJB-C | Creative Commons “images were scraped from Google and Wikimedia Commons, and Creative Commons videos were scraped from YouTube” |
| MegaFace | Downloaded images listed in YFCC100M then filtered using face detection |
| PIPA | Downloaded Creative Commons licensed photos from photo albums on Flickr |
| Who Goes There | “Our data source is the Yahoo Flickr Creative Commons 100M (YFCC100M), which contains 100 million images, of which 49 million are geotagged, and their associated metadata.” |
| YFCC100M | Randomly selected from entire Flickr corpus then filtered to “included as many photos as possible that were associated with a geographic coordinate to encourage spatiotemporal research.” |
Table: Who Used the Dataset?
Who Used the Dataset? #
According to bulk analysis of research papers citing the original research paper associated with the dataset, which types of organizations are linked to using the dataset? Linked means that a research is affiliated with that organization in the research paper, listed in download requests obtained by FOIA, or listed in a results submission pages. For example since FFHQ was developed by NVIDIA it is linked to commercial use. Because MegaFace was used by Europol and the Turkish Police it is considered linked to law enforcement use. Because PIPA was co-created by a research at Facebook it is considered linked to commercial use.
Research citations from military or defense related universities, for example the National University of Defense Technology in China, are considered linked to defense use. Research citations from military laboratories, for example the US Army Research Laboratory, are also considered linked to defense use.
Research citations from academic institutions, which are the majority of citations, are considered linked to academic use. If the academic paper acknowledges that it was funded by a defense organization, then it is also considered linked to defense use. For example, because the YFCC100M was co-created by a researcher at the Lawrence Livermore National Laboratory, a premiere national security research center; and by another co-creator at In-Q-Tel (a CIA-affiliated research organization) it is considered linked to defense use.
| Dataset | Academic | Commercial | Defense | Law Enforcement |
|---|---|---|---|---|
| COCO | Y | Y | Y | |
| DiveFace | Y | Y | ||
| FairFace | Y | Y | ||
| FDF | Y | Y | ||
| FFHQ | Y | Y | ||
| GeoFaces | Y | |||
| Google FEC | Y | |||
| IBM DiF | Y | Y | ||
| IJB-C | Y | Y | Y | |
| MegaFace | Y | Y | Y | Y |
| PIPA | Y | Y | Y | |
| Who Goes There | Y | Y | ||
| YFCC100M | Y | Y | Y | Y* |
* Indicates use in a derivative dataset. A blank entry means use is not yet known, unknowable, or could not be verified.
Table: What Is The Current Status of the Dataset?
What Is The Current Status of the Dataset? #
The following table describes the current status of the dataset. An “inactive” dataset means that the original distribution has been retracted, deactivated, or gone offline. Typically this happens without any explanation as it could potentially be seen as admission of problems with the dataset.
For example, according to FOIA documents the MegaFace stopped distribution within days of a New York Times article highlighting ethical problems with the dataset (see “ How Photos of Your Kids Are Powering Surveillance Technology” from October 2019). However, they did not mention that the MegaFace dataset is retired and unavailable until around June 2020. Similarly, the the Who Goes There dataset now returns a 404. And the GeoFaces dataset distribution page now says “Nothing to see, move along.”
| Dataset | Status | Published | Unpublished | Notes |
|---|---|---|---|---|
| COCO | Active | 2014 | Publicly available | |
| DiveFace | Active | 2019 | The list of files and metadata is publicly available, but depends on MegaFace which is offline | |
| FairFace | Active | 2019 | Publicly available | |
| FDF | Active | 2019 | Publicly available | |
| FFHQ | Active | 2019 | Publicly available | |
| GeoFaces | Inactive | 2014 | 2022 | Online throughout 2021. Offline when checked in Feb. 2022 |
| Google FEC | Active | 2018 | Publicly available | |
| IBM DiF | Inactive | 2019 | 2019 | Unpublished after 2019 NBC News article |
| IJB-C | Active | 2017 | By application | |
| MegaFace | Inactive | 2016 | 2019 | Unpublished after a 2019 New York Times article |
| PIPA | Active | 2015 | Publicly available | |
| Who Goes There | Inactive | 2016 | 2022 | Offline when checked in Feb. 2022 |
| YFCC100M | Active | 2014 | Publicly available |
Table: What Did the Dataset Include?
What Did the Dataset Include? #
The following table describes the information included in the dataset download. The term dataset has multiple meanings. For example, the YFCC100M dataset is a text file with URLS and metadata (no images and no annotations). The Google FEC includes image URLs and annotations but no metadata. The MegaFace dataset includes images and metadata but no attributions or license info. The FFHQ includes images, annotations, and metadata. Most datasets are JPG images and text files (.json, .txt, or .csv). However, the Who Goes There dataset is formatted in a HDF5 container file.
One issue with datasets that include images is they override the current status of an image. If a Flickr user were to delete or make their image private, their image still exists in the dataset. Users have not control over continued use of their image. Several datasets try to mitigate this by checking licenses before adding images to a dataset (IBM DiF did this). But if the dataset is redistributed at later point, the images are not rechecked.
| Dataset | Description |
|---|---|
| COCO | Image file and text files with annotations and CC license. No real names. Missing attribution. |
| DiveFace | Text file with name image filename in MegaFace. Racial classification using 3 labels. Gender using 2 labels. |
| FairFace | Image files, age, gender, and race metadata. |
| FDF | Image files, Flickr metadata. Some real names included if provided by Flickr user. Biometric face landmark data. CC license metadata. |
| FFHQ | Image files and text files with CC license and Flickr metadata. Some real names included if provided by Flickr user. Includes biometric face landmark data |
| Google FEC | Text file with Flickr JPG URL. Biometric emotional classification face data. |
| GeoFaces | Text file with Flickr JPG URL. |
| IBM DiF | Annotation metadata includes “craniofacial features, facial symmetry, facial contrast, skin color, age, gender, subjective annotations and pose and resolution”. Flickr username and Flickr JPG URL. |
| IJB-C | Image files. Spreadsheet with Creative Commons metadata. Links to original files. Full names of each person in dataset. |
| MegaFace | Face image files, JSON metadata files with face box and biometric face landmark data. No real name. Missing attribution. |
| PIPA | Text file with Flickr photo ID and face box coordinates. Additional text file with ink to original Flickr URL photo page and attribution. |
| Who Goes There | HDF5 data file 256x256 face chip, biometric face landmark data, age, gender, geolocation, and Flickr JPG URL. |
| YFCC100M | 12.5GB text file with Line number, Photo/video identifier, Photo/video hash, User NSID, User nickname, Date taken, Date uploaded, Capture device, Title, Description, User tags (comma-separated), Machine tags (comma-separated), Longitude, Latitude, Accuracy of the longitude and latitude coordinates (1=world level accuracy, …, 16=street level accuracy), Photo/video page URL, Photo/video download URL, License name, License URL, Photo/video server identifier, Photo/video farm identifier, Photo/video secret, Photo/video secret original, Extension of the original photo, Photos/video marker (0 = photo, 1 = video) |
Table: What Types of Potential Biometric Data Were Shared?
What Types of Potential Biometric Data Were Shared? #
The following table describes potential types of biometric data included. Further research is needed to determine if linking race, age, gender or a face box to a name is also considered non-consensual use of biometric data. But, according to the ongoing class action lawsuit against IBM for creating and distributing the IBM DiF dataset, a 68-point facial landmark can be considered biometric information because it contains biometric measurements of the face. Several of the datasets listed contain names and facial landmarks, including MegaFace, FDF, FFHQ, and Who Goes There. Only FDF and FFHQ are still actively being distributed.
| Dataset | Names* | Face Box | Face Landmarks | Face Expression | Race | Gender | Age |
|---|---|---|---|---|---|---|---|
| COCO | N | N | N | N | N | N | N |
| Dive Face | N | N | Y | N | Y | Y | N |
| Fair Face | N | N | N | N | Y | Y | Y |
| FDF | Y | Y | Y | N | Y | Y | Y |
| FFHQ | Y | Y | Y | N | N | N | N |
| GeoFaces | N | N | N | N | N | N | N |
| Google FEC | N | Y | N | Y | N | N | N |
| IJB-C | Y | N | N | N | N | N | N |
| IBM DiF* | Y | Y | |||||
| MegaFace | Y | N | Y | Y | N | N | N |
| Who Goes There | Y | Y | Y | N | N | Y | Y |
| YFCC100M | Y | N | N | N | N | N | N |
*A "Y" for real name indicates that real names were included though they may be included in the Flickr metadata because that information was provided by Flickr user. Only the IJB-C dataset provides non self-reported full names. **IBM DiF distributed a unique set of biometric data including "craniofacial features, facial symmetry, facial contrast, skin color, age, gender, subjective annotations and pose and resolution".
Table: Was Attribution Provided and Accessible?
Was Attribution Provided and Accessible? #
The following table describes if and how attribution was provided. All Creative Commons licenses with the exception of CC0 (public domain) require attribution (CC-BY). Most datasets either did not provide any attribution or provided inaccessible attribution.
For example, the FFHQ dataset includes attribution in a 256MB JSON file that could not be opened in text editor on a basic laptop. The FDF dataset provides attribution in a 1.8GB file. To understand how inaccessible this data is, it’s recommended to download the files and try to attribute a photo creator.
Download and try accessing attribution files for (open at your own risk):
- FFHQ: https://drive.google.com/open?id=16N0RV4fHI6joBuKbQAoG34V_cQk7vxSA
- FDF: https://api.loke.aws.unit.no/dlr-gui-backend-resources-content/v2/contents/links/87c06e58-a6cc-4299-81b6-c36f2bed6a0ce5810e37-59d6-4d8f-9e86-fdafe7b58c86106c2d7d-91e8-4c80-986a-0ccdbe02ddb0
For COCO you can try downloading the full zip (13GB) for the 2014 COCO training dataset but you’ll be disappointed to realize that it doesn’t even contain attribution data:
- COCO dataset: http://images.cocodataset.org/zips/train2014.zip
For IJB-C you will need to apply to NIST for approval to download it. If you’re approved (only researchers are approved), then can proceed to download 50 .tar.gz split files at 4.3GB each. Then use Terminal to concatenate the files. Then extract 213GB of image data to see any images. Then to attribute an image, you’ll need to match the filename of the image to one of two spreadsheets. Does this qualify as meaningful attribution?
| Dataset | Human | Machine | Description |
|---|---|---|---|
| COCO | N | N | Attribution not provided. Only Flickr JPG URL. |
| DiveFace | N | N | Attribution was not provided. Dataset referred to MegaFace which also did not provide attribution. |
| Fair Face | N | N | No attribution or CC license information was provided, only annotations and raw image files. |
| FDF | N | N | Attribution provided in 1.8GB JSON file. Accessible via Terminal or custom scripts. |
| FFHQ | N | Y | In a 256MB JSON file. Could not open on laptop |
| Google FEC | N | N | Attribution not provided. No CC license info provided. Only Flickr JPG URL. |
| GeoFaces | N | N | No attribution provided. No CC license info provided. Only Flickr JPG URL. |
| IBM DiF | Attribution status unknown because unable to obtain full dataset. | ||
| IJB-C | Y | Y | Attribution is provided in CSV spreadsheet files and is human readable with enough patience, but requires applying for an obtaining access to the dataset via NIST, which is only granted to researchers. |
| MegaFace | N | Y | Attribution not provided. CC license not specified. Only Flickr NSID and JPG URL provided. |
| PIPA | Y | Y | Attribution is provided in a text file and is human readable with enough patience. |
| Who Goes There | N | Y | Attribution and license information are only provided in 37GB machine readable HDF5 file. |
| YFCC100M | N | Y | Metadata is provided in a 12.5GB .tar.gz file accessible via Terminal or custom scripts. |
What Do Users Want? #
There is no simple answer to the question how images should be licensed for use in AI systems because it does depend on the usage. According to casual Twitter poll by Creative Commons in 2021 that asked “[s]hould openly licensed content (e.g. images, music, research, etc.) be used to train #AI systems?” Most respondents (48.4%) also said it “depends” while 31.6% approved and only 9% disapproved.
It would unfair to extrapolate meaningful insights from this poll because “AI systems” is too ambiguous. For instance, using GANs to generate an unlimited number of cute kittens has no meaningful overlap with a citywide 24/7 face recognition system that can provide unlimited surveillance capabilities to an authoritarian regime, though both are “AI systems”.
Since the poll is likely related to CC’s original statement about using CC images in face recognition12, it would at least slightly more fair to rephrase the poll specifically mentioning this topic. On January 29, I created my own Twitter poll to understand whether the response changes based on the wording. When the wording was changed to “Should there be a moratorium on using Creative Commons licensed Flickr photos in face recognition datasets without informed consent?” over 84% of respondents agreed while about 11% disagreed, and less than 5% did not care about the issue.
Based on popular opinion, my poll won by a landslide with over twice as many votes and a clear signal against using images for face recognition. Though, both are seriously flawed because the sample is not controlled and Twitter is an algorithmically manipulated platform. But still, an 84-to-11 victory with over twice as many votes in a poll shown to 1.2% fewer followers as the official Creative Commons account suggests that when CC photos are used for face recognition there is strong opposition. At the very least, both polls combined show strong support for a direct response from Creative Commons on the continued issue of their license enabling face recognition datasets used to develop mass surveillance technologies for authoritarian regimes.
Even Google, who previously provided face recognition to the National Security Agency (NSA), has “facial recognition restrictions” in place for their YouTube Terms of Service. It’s slightly shocking that Creative Commons lacks this clarity and common sense restriction.
Summary #
Creative Commons was well designed to address the ways images were used in 2004. They unlocked clumsy restrictions from an outdated copyright system; allowing creativity to prosper, communities to bloom, and for the Internet to become a more fun and and open place, if only temporarily. Overall, Creative Commons has been a massive success. But now Creative Commons, like the archaic copyright system it set out to reshape 18 years ago, is likewise stuck in the past. An unfortunate irony is that copyright is becoming more relevant while Creative Commons is becoming more exploitable. Adding a Creative Commons license to your work likely increases the chance of biometric data being used in academic, commercial, and defense-related research projects.
Not everyone wants to share everything with anyone. Statistics on Flickr.com show that the overwhelming majority of photos posted choose do not use Creative Commons. The revelations of the past few years show that users want more insight and transparency into how their data is being used and more control over who has access to it. Meanwhile, researches want more clarity. No one is quite sure what is legal, ethical, but a touch and go approach is going nowhere.
Based on valid polling data from Nature, and casual polling data from Creative Commons and myself; it appears users want control and researchers want clarity. One next step would be to solicit more feedback from platform users, connect with individuals whose photos were used, and expand the debate. The topic is contentious though, because it touches on the capabilities of national security and law enforcement agencies. Powerful organizations, including the CIA, FBI, and NSA rely on face recognition as an everyday tool. Face recognition is not going away anytime soon. And while there are many non-surveillance applications of “face recognition” (e.g. unlocking a phone), the dangers of this technology are becoming more apparent. In 2019, ICRAC published a dramatic video speculating how killer bots will use face recognition to identity their targets. And in 2020, the New York Times reported on the assassination of Iranian scientist with a face-recognition powered semi-autonomous rifle system13. These are no longer speculative scenarios and have not been for years.
The nature of image use has been transformed by artificial intelligence and machine learning systems. Images have a new form of collective value. When combined into datasets, images create new ways of seeing, new value, and new risks. A new license system should acknowledge these risks.
Creative Commons images are clearly valuable to AI researchers, independent and commercial alike. Most all large technology companies, at least those not shrouded in secrecy, have either benefited from Flickr datasets created by academics (see MegaFace and COCO) or are themselves the creators of face datasets using Flickr images (see PIPA, Google FEC, DiF, and FFHQ). Despite the non-commercial restrictions designated by Flickr users, their images are routinely uses by commercial organizations for commercial gain. Images from MegaFace and COCO dataset even appear in patent publications in the US and China.
The limited but illustrative examples included in this report show there exists clear cases where millions of CC images are being used for face recognition technologies and against the legal requirements of CC licenses. Therefore, it appears to amount to the large-scale exploitation of Creative Commons imagery for surveillance and profit. Creative Commons imagery has become an easy loophole to obtain free training data for any AI systems that is now routinely exploited by billion dollar surveillance and technology companies.
Acknowledgements and Credits #
This report was developed for the #AICommons project by OpenFuture.eu and is based on research for the Exposing.ai project. Funding for Exposing.ai during 2018-2021 was provided by Copenhagen Business School, Mozilla, Weizenbaum Institute, and Karlsruhe HfG. Exposing.ai is an independent research and art project developed by Adam Harvey and Jules LaPlace. For more information visit https://exposing.ai. The views expressed here are solely the views of the author and do not necessarily reflect the views of the supporting or commissioning organizations.
Unless otherwise noted or quoted all text, data analysis, and graphics ©™ by Adam Harvey 2021—2022. Written in Markdown. Charts made with MermaidJS. Published using Hugo.
Glossary #
Image Licenses #
Copyright
Creative Commons
All Creative Commons (CC) licenses include the BY attribution requirement, meaning the license CC-NC is equivalent to CC-BY-NC. The main license categories are:
- CC-BY: This license allows reusers to distribute, remix, adapt, and build upon the material in any medium or format, so long as attribution is given to the creator. The license allows for commercial use.
- CC-NC: This license allows reusers to distribute, remix, adapt, and build upon the material in any medium or format for noncommercial purposes only, and only so long as attribution is given to the creator.
- CC-ND: This license allows reusers to copy and distribute the material in any medium or format in unadapted form only, and only so long as attribution is given to the creator. The license allows for commercial use.
- CC-SA: This license allows reusers to distribute, remix, adapt, and build upon the material in any medium or format, so long as attribution is given to the creator. The license allows for commercial use. If you remix, adapt, or build upon the material, you must license the modified material under identical terms.
- CC0 / CC Zero: (aka CC Zero) is a public dedication tool, which allows creators to give up their copyright and put their works into the worldwide public domain. CC0 allows reusers to distribute, remix, adapt, and build upon the material in any medium or format, with no conditions.
- All licenses: Full details on each license can be viewed at https://creativecommons.org/about/cclicenses/
Public Domain
The public domain consists of all the creative work to which no exclusive intellectual property rights apply. Those rights may have expired, been forfeited, expressly waived, or may be inapplicable.
Government works
Most U.S. government creative works such as writing or images are copyright-free. But not everything is. So before you use a U.S. government work, check to make sure it does not fall under one of these exceptions:
For more information visit: https://www.usa.gov/government-works
Dataset Contents Analysis #
Dataset
Training dataset
Test Dataset
Validation dataset
Benchmark dataset
Scraping images
AI and Neural Networks #
Neural Network Model
Deep Convolution Neural Network (DCNN)
Refers to using convolutional network layers to learn visual features. A convolution is an image (data matrix) operation that convolves (combines) nearby visual information using a transformation function. For example, using and edge filter in a graphics editing program is a convolution matrix. Another example would be an unsharp mask, as shown in this interactive convolutional demo. Another helpful example is https://setosa.io/ev/image-kernels/.
A DCNN uses multiple layers of convolutions to understand visual features and concepts within images.
Computer Vision #
Face Recognition
Face Detection
Face Landmarks
Face Embeddings
Ethnicity Estimation
Further Reading #
Articles related to this research include:
- November 2020: Nature magazine writes about the ethical issues haunting academic research on facial recognition highlighting MegaPixels research on the Duke MTMC, Brainwash, and MS-Celeb-1M dataset in a growing debate over biometric surveillance technologies
- August 2020: A recent U.S. GAO report on facial recognition cites consent as one of the main privacy issues, referencing research from the MegaPixels project. The full 65 page report: Facial Recognition Technology: Privacy and Accuracy Issues Related to Commercial Uses.
- October 2019: New York Times writes about “ How Photos of Your Kids Are Powering Surveillance Technology”
- April 2019: Who’s Using Your Face? The Ugly Truth About Facial Recognition
References* #
Due to a small bug in the publishing system the citations within the expanded text blocks are not being automatically referenced and are manually added below:
[^merkley_2019]:https://creativecommons.org/2019/03/13/statement-on-shared-images-in-facial-recognition-ai/[^cc_ai_faq]:https://creativecommons.org/faq/#artificial-intelligence-and-cc-licenses[^cc_ai_2021]:https://creativecommons.org/2021/03/04/should-cc-licensed-content-be-used-to-train-ai-it-depends/[^flickr_cc]:https://www.flickr.com/creativecommons/. Accessed Jan. 27, 2022.[^flickr_com]:https://flickr.com. Accessed Jan. 27, 2022.[^flickr_joi_ito]:https://creativecommons.org/2009/03/23/celebrate-100-million-cc-photos-on-flickr-with-joi-itos-free-souls/[^ibg_eval_2103]:Evaluation of Online Face Processing 2013: Methodology and Results[^fairface]:FairFace: Face Attribute Dataset for Balanced Race, Gender, and Age[^megaface_benchmark]:The MegaFace Benchmark: 1 Million Faces for Recognition at Scale[^huiskes08]:New Trends and Ideas in Visual Concept Detection: The MIR Flickr Retrieval Evaluation Initiative[^solon]:https://www.nbcnews.com/tech/internet/facial-recognition-s-dirty-little-secret-millions-online-photos-scraped-n981921[^classaction_org]:https://www.classaction.org/news/class-action-accuses-ibm-of-flagrant-violations-of-illinois-biometric-privacy-law-to-develop-facial-recognition-tech[^ftc_everalbum]:https://www.ftc.gov/news-events/press-releases/2021/01/california-company-settles-ftc-allegations-it-deceived-consumers[^darby]:“In-Q-Tel President Chris Darby on Investment and Innovation in U.S. Intelligence Matters,” Intelligence Matters, podcast, April 23, 2019, https://podcasts.apple.com/us/podcast/inq-tel-president-chris-darby-on-investment-innovation/id1286906615?i=1000436184139, accessed December 6, 2021.[^yfcc100m]:YFCC100M: The New Data in Multimedia Research.[^bipa]:https://en.wikipedia.org/wiki/Biometric_Information_Privacy_Act[^hinton]:“Heroes of Deep Learning: Andrew Ng Interviews Geoffrey Hinton,” YouTube, August 8, 2017, https://www.youtube.com/watch?v=-eyhCTvrEtE, accessed December 6, 2021.[^frontline]:“In the Age of AI,” Frontline, podcast, November 14, 2019, https://podcasts.apple.com/de/podcast/frontlinefilm-audio-track-pbs/id336934080?l=en&i=1000456779283, accessed December 6, 2021.[^paglen]:Trevor Paglen. 2019. https://web.archive.org/web/20190330153654/https://imagenet-roulette.paglen.com/, accessed December 6, 2021.[^hanna]:Alex Hanna, et al., “Lines of Sight,” Logic Mag, vol. 12, https://logicmag.io/commons/lines-of-sight/, accessed December 6, 2021.[^nist_romine]:https://www.nist.gov/director/congressional-and-legislative-affairs[^nist_romine_2019]:https://www.c-span.org/video/?462439-1/facial-recognition-biometric-technologies[^nyt_ai_kill]:https://www.nytimes.com/2021/09/18/world/middleeast/iran-nuclear-fakhrizadeh-assassination-israel.html[^wikipedia_llnl]:Lawrence Livermore National Laboratory. Accessed November 2021. https://en.wikipedia.org/wiki/Lawrence_Livermore_National_Laboratory[^Morales2020SensitiveNetsLA]:“SensitiveNets: Learning Agnostic Representations with Application to Face Images”
References #
Auto-generated
https://www.c-span.org/video/?462439-1/facial-recognition-biometric-technologies ↩︎
https://www.nist.gov/director/congressional-and-legislative-affairs ↩︎
“Heroes of Deep Learning: Andrew Ng Interviews Geoffrey Hinton,” YouTube, August 8, 2017, https://www.youtube.com/watch?v=-eyhCTvrEtE, accessed December 6, 2021. ↩︎
“In the Age of AI,” Frontline, podcast, November 14, 2019, https://podcasts.apple.com/de/podcast/frontlinefilm-audio-track-pbs/id336934080?l=en&i=1000456779283, accessed December 6, 2021. ↩︎
“In-Q-Tel President Chris Darby on Investment and Innovation in U.S. Intelligence Matters,” Intelligence Matters, podcast, April 23, 2019, https://podcasts.apple.com/us/podcast/inq-tel-president-chris-darby-on-investment-innovation/id1286906615?i=1000436184139, accessed December 6, 2021. ↩︎
https://creativecommons.org/2009/03/23/celebrate-100-million-cc-photos-on-flickr-with-joi-itos-free-souls/ ↩︎
https://www.flickr.com/creativecommons/. Accessed Jan. 27, 2022. ↩︎
https://flickr.com. Accessed Jan. 27, 2022. ↩︎
New Trends and Ideas in Visual Concept Detection: The MIR Flickr Retrieval Evaluation Initiative ↩︎
Lawrence Livermore National Laboratory. Accessed November 2021. https://en.wikipedia.org/wiki/Lawrence_Livermore_National_Laboratory ↩︎
https://creativecommons.org/2019/03/13/statement-on-shared-images-in-facial-recognition-ai/ ↩︎
https://www.nytimes.com/2021/09/18/world/middleeast/iran-nuclear-fakhrizadeh-assassination-israel.html ↩︎