Origins and Endpoints of Image Training Datasets Created “In the Wild”
Written in 2020 and published in 2021 as part of Practicing Sovereignty, a collection of essays on “Digital Involvement in Times of Crises”.
Abstract #
Face recognition and biometric research are contributing to rapid growth in new biometric surveillance technologies. But many of the datasets used for these technologies rely on media collected from non-consensual, non-regulated sources. Researchers call this “media in the wild”. This analysis examines the widespread and largely unregulated use of images “in the wild” that were captured from campuses, CCTV camera feeds, social media, celebrity databases, and by scraping Internet search engines. The findings presented here show that millions of individuals have unknowingly been used for training face recognition and other biometric analysis algorithms in both academic and commercial applications. Data compiled for this project, along with more in depth analyses for each dataset, is available on the research project website https://exposing.ai.
Overview #
Image training datasets are an essential technical component of Artificial Intelligence (AI) that often operate out of sight. Without sufficiently large datasets to train on, AI could not compute anything. As Chris Darby, president and CEO of In-Q-Tel (C.I.A.’s strategic investment firm) stated: “an algorithm without data is useless.”1 Geoffrey Hinton describes the importance of datasets as central to understanding new forms of computation. “Our relationship to computers has changed” Hinton says. “Instead of programming them, we now show them and they figure it out.”2 Kai-Fu Lee claims that “AI is basically run on data.”3 The new logic is not better algorithms; it is better data, and more data. “The more data the better the AI works, more brilliantly than how the researcher is working on the problem” says Lee. But if data is the bedrock of AI systems, the foundation should be solid. Instead, many of the datasets currently used to train, test, and validate face recognition and other biometric surveillance technologies are built on an unstable foundation of data collected without consent or oversight. Researchers call this approach “in the wild”, referring to the assumed natural or unconstrained quality of the data. This research examines where these datasets originate and where they are being used. In response to this research, several dataset authors retracted or stopped distributing their datasets, deleted websites, or made formal apologies for ethical breaches in their data collection methods. The status of each dataset is described on its corresponding analysis page at https://exposing.ai/datasets.
Background #
Within the field of AI, face recognition is one of the most concerning applications. In the United States, over a dozen cities have now banned face recognition, citing civil rights concerns and the potential for abuse by law enforcement agencies. Face recognition technologies are also disproportionately more threatening because of the decreased accuracy for minority racial groups45, reflecting the biased data they were trained with. Several researchers have addressed the former issue by creating more diverse face datasets, and companies have responded by pledging to address this bias with algorithms that learn more from underrepresented classes. But another issue remains: how are these datasets being created, and is anyone consenting to being used for biometric research experiments?
This answer requires a collective voice, as face recognition algorithms are a collective technology that requires millions of faces from millions of people. Determining the similarity of one person to another requires the encoded knowledge of multiple identities. A face recognition system’s utility is its capacity to understand the difference between a theoretically limitless variety of biometric appearances. But this assumes a limitless pool of training data and a complementary scale of computational power. In reality, resources are limited. Academic researchers, seeking to participate in the field of face recognition or face analysis, have long sought open, shareable resources to innovate new ideas. In the United States, where a significant amount of academic facial recognition research was funded as a response to the 9/11 attacks, universities lacked access to datasets, which were critical to advancing research. According to the authors of FERET, the first public face recognition benchmark, “[t]wo of the most critical requirements in support of producing reliable face-recognition systems are a large database of facial images and a testing procedure to evaluate systems.”6
In 2007, a landmark face recognition benchmarking dataset called Labeled Faces in The Wild (LFW)7 was first introduced to address these requirements. LFW is based on a previous dataset collected in 2003 called “Names and Faces in The News” that contained half a million captioned news images from Yahoo! News.8 The LFW dataset includes 13,233 images from 5,749 individuals. According to an article on BiometricUpdate.com, a popular site for biometric industry professional, LFW eventually became “the most widely used evaluation set in the field of facial recognition.”9 The success of the LFW face dataset helped catalyze and normalize the trend for “media in the wild”. During the next decade, researchers replicated their success in dozens more datasets.
At the same time, corporations were amassing far larger face datasets but these were off limits to academic research and public benchmarks. Google reportedly build an internal dataset of over 200 million images and 8 million identities, while Facebook has over 500 million images from 10 million identities.10 Engineers and researchers, locked out of the proprietary data sources controlled by corporations or government agencies, sought alternative data collection methods to make face recognition research more widely accessible. This led to the surge in the usage and development of biometric datasets created “in the wild” that could be used for both training and public benchmarking.
Methodology #
To understand how this shift in data collection has evolved, a system was developed to categorize, track, and visualize datasets by analyzing and geocoding the research citations associated with each dataset. Rather than rely on the researcher’s initial intended purpose and purview to understand how a dataset is impacting society, this analysis reframes datasets as a biometric commodity in a global information supply chain. This research maps the transnational flow of dataset, as a global commodity, that powers a growing crisis of biometric surveillance technologies.
The geographic information for each dataset is inferred by using the author’s stated affiliation in the front matter of publicly available research papers. Typically, a research paper is published coinciding with the release of a new dataset. This becomes the starting point to then analyze the geographic metadata in other research publications that cite the original work. For each dataset, hundred or thousands of PDFs are located and then manually reviewed to verify whether the researchers would have needed to download the data in order to conduct their research. Broadly, this includes researchers using datasets as part of a research methodology, including as training, fine-tuning, or as verification or validation data. Research papers are omitted that only mention the dataset in passing as related research, which purely cite methodology in the original paper such as algorithms or pre-trained models, or use models pre-trained on a dataset because this does not prove that the researchers acquired the images. Because geocoding based on researchers report affiliation makes an assumption that the researcher’s self-reported organization is correct, and that they were operating at that location during the time of their research, the inferred geographic data visualized in the information supply chain maps should be understood as a proxy for revealing the global trends associated with a particular dataset, with each point on the map understood as a confirmed usage but in an approximate location.
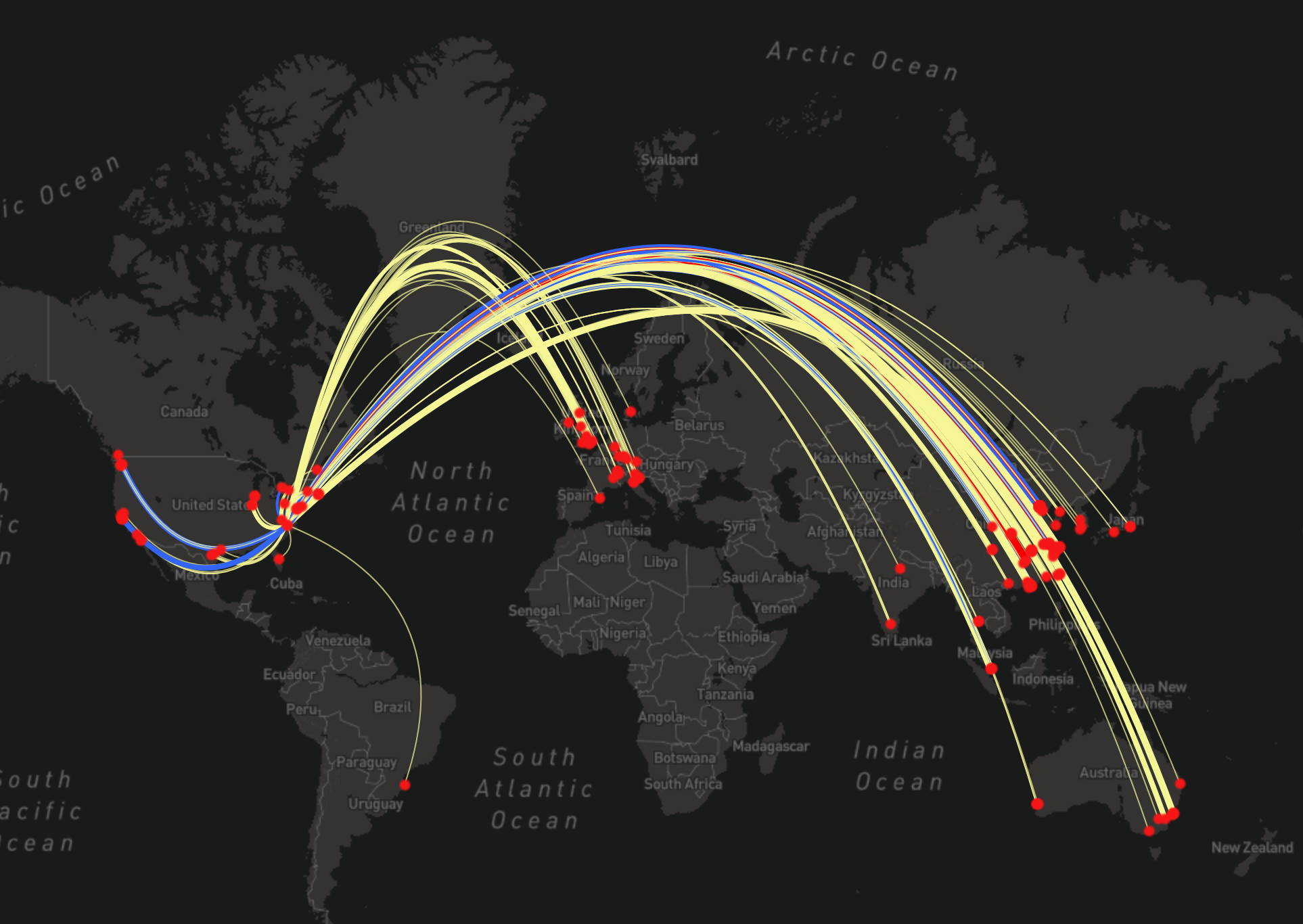
A visualization of the inferred usage locations for the Duke MTMC datasets. The data originated at university campus in North Carolina and eventually became one of the most widely cited training datasets for building surveillance technologies.
Next, the verified set of research papers are again reviewed for insights into the types of organizations using the data. As an example, we applied this methodology to a dataset created from a cafe in San Francisco called Brainwash11. The dataset was created by a researcher at Stanford University, who recorded the cafe’s livestream with the help of AngelCam.com and then used it to create a head detection dataset. Publicly available research uncovered during our analysis showed that images from the cafe in San Francisco were eventually used by the National University of Defense Technology in China, a military research organization affiliated with the People’s Liberation Army. As a result of our investigation, the dataset was terminated by Stanford University, which triggered mainstream media articles cautioning against this type of rogue data acquisition12. Brainwash is one example among hundreds which are being analyzed and published on our research project website exposing.ai that follow a similar trend.
Datasets “In The Wild” #
Among the hundreds of other datasets created in the wild, over a dozen inherit the same nomenclature of the popular LFW dataset. An illustrative but non-exhaustive list of datasets using “in the wild” in their title include “300 Faces In-the-Wild”, “Affect in the Wild Challenge”, “Annotated Faces in the Wild”, “Annotated Facial Landmarks in the Wild”, “Appearance-based Gaze Estimation in-the-Wild”, “Biased Faces in the Wild”, “Caltech Occluded Faces in the Wild”, “Cross Pose Labeled Faces in the Wild”, “Disguised Faces in the Wild”, “Expression in the Wild”, “Faces in the Wild”, “Families in the Wild”, “Grouping Face in the Wild (GFW) Dataset”, “High Quality Faces in the Wild”, HUST-LEBW Eyeblink in the Wild Dataset", “ibug Deformable Models of Ears In-The-Wild”, “In-The-Wild Child Celebrity”, “Labeled Face Parts in the Wild”, “LAOFIW – Labeled Ancestral Faces in the Wild”, “Makeup in-the-Wild”, “Person Re-Identification in-the-Wild”, “Racial Faces in the Wild”, and “Valence and Arousal Estimation In-The-Wild”.
Datasets make reference to their predecessors, using similar format for the files and annotations. But every dataset is unique and custom-made. There is no standard way data is collected or represented in a training dataset. And because dataset usage changes over time, an existing dataset might transform into a new dataset by being edited, re-annotated, or combined with other sources. Instead of grouping the datasets by their initial intended applications or formats, which are unstable over time, we use their origin as a taxonomy for classification, broadly grouping the datasets into 4 themes: campuses and universities, CCTV or livestream feeds, social media, and celebrity databases and web scraping.
Campus Images of Students #
Images of students collected on campuses appear frequently in unconstrained datasets “in the wild”. In the United States, several datasets were discovered that exploited campuses as a source of training data.
Duke MTMC #
In 2016, a researcher at Duke University in North Carolina created a dataset of student images called Duke MTMC, or multi-target multi-camera. The Duke MTMC dataset contains over 14 hours of synchronized surveillance video from 8 cameras at 1080p and 60 FPS, with over 2 million frames of 2,000 students walking to and from classes. The 8 surveillance cameras deployed on campus were specifically setup to capture students “during periods between lectures, when pedestrian traffic is heavy”.13 The dataset became widely popular and over 100 publicly available research papers were discovered that used the dataset. These papers were analyzed according to methodology described earlier to understand the endpoints: who is using the dataset, and how it is being used. The results show that the Duke MTMC dataset spread far beyond its origins and intentions in academic research projects at Duke University. Since its publication in 2016, more than twice as many research citations originated in China as in the United States. Among these citations were papers linked to the Chinese military and several companies known to provide Chinese authorities with the oppressive surveillance technology used to monitor millions of Uighur Muslims.

A video still frame from the original Duke MTMC dataset recorded at Duke University without consent from the students.
In one 2018 research paper jointly published by researchers from SenseNets and SenseTime entitled “Attention-Aware Compositional Network for Person Re-identification”14, the Duke MTMC dataset was used for “extensive experiments” on improving person re-identification across multiple surveillance cameras, with important applications in suspect tracking. Both SenseNets and SenseTime have provided surveillance technology to monitor Uighur Muslims in China.15
Despite warnings 16 that the authoritarian surveillance used in China represents a humanitarian crisis, researchers at Duke University unknowingly continued to provide open access to their dataset for anyone to use for any project. As the surveillance crisis in China grew, so did the number of citations with links to organizations complicit in the crisis. In 2018 alone there were over 90 research projects happening in China that publicly acknowledged using the Duke MTMC dataset. Among these were projects from CloudWalk, Hikvision, Megvii (Face++), SenseNets, SenseTime, Beihang University, China’s National University of Defense Technology, and the PLA’s Army Engineering University, several of which have been added to a trade blacklist by the United States Commerce Department.
In response to our research and joint investigation with the Financial Times17, the author of Duke MTMC terminated their website. The local student newspaper then published several articles about the issue, and the author responded by making a formal apology to the student body, admitting that the dataset was a violation of Duke’s ethics standards.
Unconstrained College Students Dataset #
A similar story occurred at a campus in Colorado where university faculty used a long-range high-resolution surveillance camera and photographed students without their knowledge for a face recognition benchmarking dataset called UnConstrained College Students (UCCS).

An image of students in the UCCS dataset that was surreptitiously photographed with a long-range camera for use in facial recognition experiments. Faces are redacted for privacy.
The UCCS dataset includes over 1,700 unique identities of students and faculty walking to and from class. The photos were taken during the spring semesters of school year 2012–2013 on the West Lawn of the University of Colorado Colorado Springs campus, using a Canon 7D 18-megapixel digital camera fitted with a Sigma 800mm F5.6 EX APO DG HSM telephoto lens, pointed out an office window across the university’s West Lawn. “The camera [was] programmed to start capturing images at specific time intervals between classes to maximize the number of faces being captured.”18 Their setup made it impossible for students to know they were being photographed, providing the researchers with realistic, unconstrained, surveillance images to help build face recognition systems for real world applications by defense, intelligence, and commercial partners. In fact, the dataset was funded by Intelligence Advanced Research Projects Activity (IARPA), Office of Director of National Intelligence (ODNI), Office of Naval Research and The Department of Defense Multidisciplinary University Research Initiative (ONR MURI), and the Special Operations Command and Small Business Innovation Research (SOCOM SBIR). A University of Colorado Colorado Springs website also explicitly states their involvement in the IARPA Janus face recognition project is developed to serve the needs of national intelligence, establishing that the dataset of student images was created in the interest of United States defense and intelligence agencies.
Wildtrack Dataset #
In another dataset originating in Zurich called Wildtrack, researchers made video recordings of students outside the ETH university main building. The videos were acquired in an “unscripted,” “non-actor but realistic environment,” 19 implying forced consent. In total, seven 35 minute videos containing thousands of students were surreptitiously recorded and made publicly available for any type of research. Though the researchers described posting signs to inform students of what was happening20, reviewing the videos shows that the vast majority of students were nonplussed. One student gave a camera the middle finger and then walked away.

A still image from Wildtrack dataset collected at EHZ Zurich, where researchers recorded students and publicly distributed their videos for surveillance research. The image is annotated to track students across multiple video frames.
The dataset eventually surfaced in a research paper on UAV surveillance at the International Conference on Systems and Informatics, where researchers affiliated with Nanjing University of Aeronautics and the University of Leicester proposed a new method for detecting and tracking small targets from UAV surveillance feeds with applications for “conducting aerial surveillance.”21 Figures published in their research paper confirm that video recordings of students at ETH Zurich were used for research and development of foreign UAV surveillance technologies.
CCTV and Livecam Images #
On October 27, November 13, and November 24 in 2014 a researcher at Stanford worked with Angelcam.com11 to create a dataset called Brainwash. The dataset includes 11,917 images of “everyday life of a busy downtown cafe” captured at 100 second intervals throughout the day. The Brainwash dataset is notable, as mentioned previously, because the images of people in a San Francisco cafe were eventually used in multiple projects by researchers affiliated with the National University of Defense Technology in China. Brainwash is no longer distributed by Stanford, but unlike researchers at Duke, the researchers at Stanford did not provide any apology or admission of ethical breach.

Still images from the Brainwash dataset created from a livecam feed from a cafe in San Francisco that was in multiple research projects for developing head detection algorithms.
Images from CCTV or security cameras provide another frequent source of data. In this case, the data is most similar to the potential environment in which it would be deployed, but the scale of these datasets is often smaller and less accessible. Datasets created from CCTV feeds include MrSub and Clifton, datasets of surveillance images from a sandwich shop used for head detection; Grand Central Station Dataset, CCTV videos from Grand Central Station in New York City used for pedestrian tracking; QMUL GRID, a dataset of commuters from the London Underground that was released by the UK Ministry of Defence for the development of person tracking technologies; and Oxford Town Centre, a dataset of pedestrians in Oxford originally created for the development of head stabilization technologies used in face recognition systems.
The Oxford Town Centre CCTV video was obtained from a surveillance camera at the corner of Cornmarket and Market St. in Oxford, England and includes approximately 2,200 people. Since its publication in 200922 the Oxford Town Centre dataset has been used in over 60 verified research projects including research affiliated with Amazon, Disney, OSRAM, Sony, Volvo, and Huawei; and academic research in China, Israel, Russia, Singapore, the US, and Germany, among dozens more.
The Oxford Town Centre dataset is unique in that it uses footage from a public surveillance camera that would otherwise be designated for public safety. The video shows that the pedestrians act normally and unrehearsed indicating they neither knew of nor consented to participation in the research project. In June 2020, the website for Oxford Town Centre was taken down with no announcement or apology from the researchers.
Social Media Images #
Social media images provide the second largest source of data “in the wild”, with Flickr.com as the single largest source of data for face recognition and face analysis related experiments. The largest dataset, though not entirely comprised of faces, is called “Yahoo! Flickr Creative Commons 100 Million” or YFCC100M. As the name implies, it includes 100 million media objects with Creative Commons licenses. The YFCC100M dataset is the origin of one of the largest publicly available face recognition training datasets, called MegaFace.

408 of about 4,753,520 face images from the MegaFace face recognition training and benchmarking dataset. Faces are blurred to protect privacy. Visualization by Adam Harvey / Exposing.ai licensed under CC-BY-NC with original images licensed and attributed under Creative Commons CC-BY.
MegaFace23 is a large-scale, public face recognition training dataset that serves as one of the most important benchmarks for commercial face recognition vendors. It includes 4,753,320 faces of 672,057 identities from 3,311,471 photos downloaded from 48,383 Flickr users’ photo albums. All photos included a Creative Commons license, but most were not licensed for commercial use.
MegaFace has appeared in research projects affiliated with Alibaba, Amazon, Google, CyberLink, IntelliVision, N-TechLab (FindFace.pro), Mitsubishi, Orion Star Technology, Philips, Samsung, SenseTime, Sogou, Tencent, and Vision Semantics, to name only a few. A public records request by New York Times reporter Kashmir Hill revealed that the dataset was also used by the Turkish Police, Danish National Police, Russian security and defense contractor Stilsoft, American defense contractor Northrop Grumman, and Hoan Ton-That, the founder of controversial face recognition company Clearview.ai. Additionally, according to the press release from the University of Washington where the dataset was created, “more than 300 research groups [were] working with MegaFace” as of 2016, most of which are commercial. A New York Times investigation into the MegaFace dataset located and interviewed several people whose photos were in the dataset, most of whom were disturbed to learn how their photos were being used.24
Images from Flickr were also used to build the Who Goes There and GeoFaces datasets, which were used for racial and ethnicity profiling in research projects that tried to convert a face into a GPS location. 25
Other datasets exploiting Creative Commons for facial training data include People In Photo Albums (PIPA), a dataset created by researchers from Facebook to improve face recognition algorithms; Labeled Ancestral Faces in The Wild (LAOFIW), that used Flickr images for ethnicity profiling; Adience, a dataset of Flickr images used for age and gender estimation algorithms; IBM Diversity in Faces, a dataset of images derived from the YFCC100M Flickr dataset used to address bias in commercial face recognition research; and Flickr Faces High Quality (FFHQ), another dataset of Flickr images created by researchers from NVIDIA and used for synthetic face generation experiments.
In total, our research discovered over 30 datasets using Flickr images. Many of these datasets overlap or comprise combinations of other datasets. Not all are used explicitly for face recognition though all datasets have, in different ways, contributed the growth of remote biometric surveillance and analysis technologies. For example, images from MS-COCO are used for person and object detection, and person detection overlaps with person re-identification surveillance technologies. Images from the USED and RESEED datasets were primarily used for social event or activity recognition, and activity priority objective in the Defense Advanced Research Projects Activity (DARPA) Minds Eye program.26 Taxonomies often overlap and datasets become reused over time, but often this can be traced back to defense or military application. For example, the LFW dataset was originally created by academics at the University of the Massachusetts and it later received funding from the Central Intelligence Agency and the National Security Agency.27
Collectively, the datasets we analyze can be described as contributing to remote biometric analysis, with overlapping applications in hard biometrics (face recognition), soft biometrics (gender, age, and facial attributes), social relationship analysis (interface analysis within groups), person re-identification, and activity recognition, which collectively align with the advancement of surveillance technologies in commercial and defense applications.
Public Figure and Celebrity Images #
The largest source of data “in the wild” is images of celebrities and public figures. Though this data is less “wild” because it comprises publicity and event photos with a cast of celebrities that often reflects structural inequalities in a society and replicates their bias, it also provides a higher quantity of images per person, which enables new types of face research. Because public figures and celebrities can remain popular over time, datasets have been created to exploit individual age diversity over decades of photos.

A mosaic of images from the MS-Celeb-1M face recognition dataset.
For example, the Cross-Age Celebrity Dataset28 uses photos from 2,000 subjects in the Internet Movie Database (IMDb) to construct a facial recognition training dataset capable of recognizing people with age disparities from a query face photo. IMDb is cited as the source for several more celebrity face recognition datasets, including CASIA-Webface29, a dataset of 10,575 subjects; and IMDb-Wiki30, a dataset of 20,284 subjects used mostly for age and gender estimation research.
The largest source of face recognition training data is the Microsoft Celeb (MS-Celeb-1M) dataset.31 It includes 10,000,000 images from 100,000 subjects, with a target list of 900,000 more subjects bringing the total list of names used in the project to 1,000,000. Microsoft’s goal in building this dataset was to distribute an initial training dataset of 100,000 individuals’ biometric data to accelerate research into recognizing a larger target list of one million people “using all the possibly collected face images of this individual on the web as training data”.31
While the majority of people in this dataset are American and British actors, the exploitative use of the term “celebrity” extends far beyond Hollywood. Many of the names in the MS Celeb face recognition dataset are merely people who must maintain an online presence for their professional lives: journalists, artists, musicians, activists, policy makers, writers, and academics. Many people in the target list are even vocal critics of the very technology Microsoft is using their name and biometric information to build. It includes digital rights activists like Jillian York; artists critical of surveillance including Trevor Paglen, Jill Magid, and Aram Bartholl; Intercept founders Laura Poitras, Jeremy Scahill, and Glenn Greenwald; Data and Society founder danah boyd; Shoshana Zuboff, author of “Surveillance Capitalism”; and even Julie Brill, the former FTC commissioner responsible for protecting consumer privacy.
Microsoft didn’t only create MS Celeb for other researchers to use; they also used it internally. In a publicly available 2017 Microsoft Research project called “One-shot Face Recognition by Promoting Underrepresented Classes,” Microsoft used the MS Celeb face dataset to build their algorithms and advertise the results. Microsoft’s corporate version of the paper does not mention that they used the MS Celeb dataset, but the open-access version published on arxiv.org does, stating that Microsoft analyzed their algorithms “on the MS-Celeb-1M low-shot learning benchmark task”.32
Despite the recent termination of the msceleb.org website, the dataset still exists in several repositories on GitHub and on the hard drives of countless researchers, on AcademicTorrents.org, and will likely continue to be used in research projects around the world. For example, the MS Celeb dataset was used for a competition called “Lightweight Face Recognition Challenge & Workshop,” where the best face recognition entries received monetary awards. The organizers of the workshop provide the MS-Celeb-1M data as a 250GB file containing the cropped faces.33
In June 2019, after Microsoft had taken down the dataset website, MS Celeb reemerged on Academic Torrents, where it has been downloaded hundreds of times without any restrictions. MS Celeb was also repackaged into another face dataset called Racial Faces in the Wild (RFW). To create it, the RFW authors uploaded face images from the MS-Celeb-1M dataset to the Face++ API and used the inferred racial scores to segregate people into four subsets: Caucasian, Asian, Indian, and African, each with 3,000 subjects.
Meanwhile, Microsoft researchers never actually stopped using the MS-Celeb-1M dataset. A November 2019 research paper posted to the pre-print server Arxiv titled “A Scalable Approach for Facial Action Unit Classifier Training Using Noisy Data for Pre-Training”34 cites using “the large scale publicly available MS-Celeb-1M dataset” for “the pre-training stage” of building automated facial action unit classification technology. The author of the paper is affiliated with Microsoft Research.
Conclusion #
From one perspective, “in the wild” is an ideal characteristic for training data because it can provide a closer match to an unknown deployment environment. Theoretically, this can improve real-world performance by reducing disparity and bias. In reality, data collected from sources “in the wild” inherit new problems including the systemic inequalities within society and are never “natural” or “wild”. Representing datasets as unconstrained or “wild” simplifies complexities in the real world where nothing is free from bias. Further, collecting data without consent forces people to unknowingly participate in experiments which may violate human rights.
However, for certain types of datasets or applications, it may in the public interest to provide publicly accessible data. Not all datasets contain faces or biometric information. Creative Commons licenses were designed to unlock the restrictive nature of copyright and allow creators to share and remix each other’s work. Allowing Creative Commons images for machine learning and artificial intelligence applications may be a helpful public utility, as their CEO 35 has noted, but only if better regulations are created to protect biometric information that could otherwise be easily exploited for surveillance and biometric technologies with serious implications for privacy and human rights. Currently Creative Commons is not interested in such a license, but this research suggests that action is far overdue. Until Creative Commons makes drastic changes, it is advisable to stop using Creative Commons for all images containing people, as it offers no meaningful protection against misuse in the era of Artificial Intelligence and training datasets and likely increases the chance of your photos becoming biometric “media in the wild”.
To check if your Creative Commons images have been used in facial recognition experiments, check the Exposing.ai search engine at https://exposing.ai/search.
© Adam Harvey 2020. All Rights Reserved.
Notes: Text has been updated in this version to reflect updates made to the project since publication, including changing the project name from MegaPixels.cc to Exposing.ai, along with several typo corrections and clarifications. Last updated November 14, 2021.
Originally published in “Practicing Sovereignty: Digital Involvement in Times of Crises” https://www.transcript-publishing.com/978-3-8376-5760-9/practicing-sovereignty/
References #
Darby, Chris. 2019. “‘In-Q-Tel President Chris Darby on Investment and Innovation in U.S. Intelligence Intelligence Matters’.” April 23, 2019, Podcast,. https://podcasts.apple.com/us/podcast/in-q-tel-president-chris-darby-on-investment-innovation/id1286906615?i=1000436184139. ↩︎
Hinton, Geoffrey. 2017. “Heroes of Deep Learning.” August 8, 2017. Video. https://www.youtube.com/watch?v=-eyhCTvrEtE. ↩︎
Lee, Kaifu. 2019. “Frontline: In the Age of Ai.” November 14, 2019. Podcast. https://podcasts.apple.com/de/podcast/frontline-film-audio-track-pbs/id336934080?l=en&i=1000456779283. ↩︎
Burton-Harris, Victoria, and Philip Mayor. 2020. “‘Wrongfully Arrested Because Face Recognition Can’t Tell Black People Apart’.” June 24, 2020, June. ACLU.org. https://www.aclu.org/news/privacy-technology/wrongfully-arrested-because-face-recognition-cant-tell-black-people-apart/. ↩︎
Grother, Patrick J., M. Ngan, and Kayee K. Hanaoka. 2019. “Face Recognition Vendor Test Part 3:: Demographic Effects.” In. ↩︎
Phillips, P., H. Moon, Patrick J. Rauss, and S. A. Rizvi. 1997. “The Feret Evaluation Methodology for Face-Recognition Algorithms.” Proceedings of IEEE Computer Society Conference on Computer Vision and Pattern Recognition, 137–43. ↩︎
Huang, G., M. Mattar, T. Berg, and Eric Learned-Miller. 2008. “Labeled Faces in the Wild: A Database forStudying Face Recognition in Unconstrained Environments.” In. ↩︎
Berg, T., A. Berg, Jaety Edwards, M. Maire, R. White, Y. Teh, E. Learned-Miller, and D. Forsyth. 2004. “Names and Faces in the News.” In CVPR 2004. ↩︎
Lee, Justin. 2017. “‘PING an Tech Facial Recognition Receives High Score in Latest Lfw Test Results’.” February 13, 2017, February. BiometricUpdate.com. https://www.biometricupdate.com/201702/ping-an-tech-facial-recognition-receives-high-score-in-latest-lfw-test-results. ↩︎
Bansal, Ankan, Anirudh Nanduri, Carlos D. Castillo, Rajeev Ranjan, and R. Chellappa. 2017. “UMDFaces: An Annotated Face Dataset for Training Deep Networks.” 2017 IEEE International Joint Conference on Biometrics (IJCB), 464–73. ↩︎
Stewart, R., M. Andriluka, and A. Ng. 2016. “End-to-End People Detection in Crowded Scenes.” 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2325–33. ↩︎ ↩︎
Metz, Cade. 2019. “Facial Recognition Tech Is Growing Stronger, Thanks to Your Face.” July 13 2019, July. New York Times. https://www.nytimes.com/2019/07/13/technology/databases-faces-facial-recognition-technology.html. ↩︎
Ristani, Ergys, Francesco Solera, Roger S. Zou, R. Cucchiara, and Carlo Tomasi. 2016. “Performance Measures and a Data Set for Multi-Target, Multi-Camera Tracking.” In ECCV Workshops. ↩︎
Xu, J., R. Zhao, Feng Zhu, Huaming Wang, and Wanli Ouyang. 2018. “Attention-Aware Compositional Network for Person Re-Identification.” 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2119–28. ↩︎
Mozur, Paul. 2019. “‘One Month, 500,000 Face Scans: How China Is Using a.I. to Profile a Minority’.” April 14, 2019, April. The New York Times. https://www.nytimes.com/2019/04/14/technology/china-surveillance-artificial-intelligence-racial-profiling.html. ↩︎
Watch, Human Rights. 2019. “‘China: Police “Big Data” Systems Violate Privacy, Target Dissent’.” November 19, 2017, April. Human Rights Watch. https://www.hrw.org/news/2017/11/19/china-police-big-data-systems-violate-privacy-target-dissent. ↩︎
Murgia, Madhumita. 2019. “Who’s Using Your Face? The Ugly Truth About Facial Recognition.” September 18 2019, April. Financial Times. https://www.ft.com/content/cf19b956-60a2-11e9-b285-3acd5d43599e. ↩︎
Günther, M., Peiyun Hu, Christian Herrmann, Chi-Ho Chan, Min Jiang, Shunchuang Yang, Akshay Raj Dhamija, et al. 2017. “Unconstrained Face Detection and Open-Set Face Recognition Challenge.” 2017 IEEE International Joint Conference on Biometrics (IJCB), 697–706. ↩︎
Chavdarova, Tatjana, Pierre Baqué, Stéphane Bouquet, Andrii Maksai, Cijo Jose, Louis Lettry, Pascal Fua, Luc Van Gool, and François Fleuret. 2017. “The Wildtrack Multi-Camera Person Dataset.” ArXiv abs/1707.09299. ↩︎
Kormann, Judith. 2020. “‘Wie Unsere Bilder Zu überwachungstechnologie Beitragen’.” November 3, 2020, November. Neue Zurcher Zeitung. https://www.nzz.ch/schweiz/ueberwachung-wie-unsere-bilder-die-technologie-verbessern-ld.1542751. ↩︎
Xiang, C., Haochen Shi, Ning Li, M. Ding, and Huiyu Zhou. 2019. “Pedestrian Detection Under Unmanned Aerial Vehicle an Improved Single-Stage Detector Based on Retinanet.” 2019 12th International Congress on Image and Signal Processing, BioMedical Engineering and Informatics (CISP-BMEI), 1–6. ↩︎
Benfold, Ben, and I. Reid. 2009. “Guiding Visual Surveillance by Tracking Human Attention.” In BMVC. ↩︎
Nech, Aaron, and Ira Kemelmacher-Shlizerman. 2017. “Level Playing Field for Million Scale Face Recognition.” 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 3406–15. ↩︎
Hill, Kashmir. 2019. “‘How Photos of Your Kids Are Powering Surveillance Technology’.” October 10 2019, October. New York Times. https://www.nytimes.com/interactive/2019/10/11/technology/flickr-facial-recognition.html. ↩︎
Islam, Mohammad T., Connor Greenwell, Richard Souvenir, and Nathan Jacobs. 2015. “Large-Scale Geo-Facial Image Analysis.” EURASIP Journal on Image and Video Processing 2015: 1–17. ↩︎
Bouma, H., P. Hanckmann, J. Marck, Leo Penning, R. D. den Hollander, J. ten Hove, Sebastiaan P. van den Broek, K. Schutte, and G. Burghouts. 2012. “Automatic Human Action Recognition in a Scene from Visual Inputs.” In Defense + Commercial Sensing. ↩︎
Jain, Vidit, E. Learned-Miller, and A. McCallum. 2007. “People-Lda: Anchoring Topics to People Using Face Recognition.” 2007 IEEE 11th International Conference on Computer Vision, 1–8. ↩︎
Liu, C., S. Gong, and Chen Change Loy. 2014. “On-the-Fly Feature Importance Mining for Person Re-Identification.” Pattern Recognit. 47: 1602–15. ↩︎
Yi, Dong, Zhen Lei, S. Liao, and S. Li. 2014. “Learning Face Representation from Scratch.” ArXiv abs/1411.7923. ↩︎
Rothe, R., R. Timofte, and L. Gool. 2015. “DEX: Deep Expectation of Apparent Age from a Single Image.” 2015 IEEE International Conference on Computer Vision Workshop (ICCVW), 252–57. ↩︎
Guo, Yandong, Lei Zhang, Yuxiao Hu, X. He, and Jianfeng Gao. 2016. “MS-Celeb-1m: A Dataset and Benchmark for Large-Scale Face Recognition.” In ECCV. ↩︎ ↩︎
Guo, Yandong, and L. Zhang. 2017. “One-Shot Face Recognition by Promoting Underrepresented Classes.” ArXiv abs/1707.05574. ↩︎
“Lightweight Face Recognition Challenge & Workshop.” 2019. 2019. Website. https://ibug.doc.ic.ac.uk/resources/lightweight-face-recognition-challenge-workshop/. ↩︎
Fung, Alberto, and Daniel McDuff. 2019. “A Scalable Approach for Facial Action Unit Classifier Training Using Noisy Data for Pre-Training.” ArXiv abs/1911.05946. ↩︎
Merkley, Ryan. 2019. “‘Use and Fair Use: Statement on Shared Images in Facial Recognition Ai’.” March 13, 20198, March. Creative Commons. https://creativecommons.org/2019/03/13/statement-on-shared-images-in-facial-recognition-ai/. ↩︎